Sequence to Sequence Model
the-lectures
machine-learning
Encoder-Decoder 구조를 알아보자.
TL; DR
생성형 모델의 원조 같은 seq2seq 모델을 배워보자.
넋두리
비로소 (트랜스포머까지 이르는) ’목전’까지 온 느낌이다. Seq2Seq 모델은 이쪽의 정보를 압축해서 저쪽에 보내고 이를 다시 저쪽의 맥락에서 풀어내는 것을 의미한다. 전형적으로 ’번역’을 생각하면 되겠다. 강의 역시 영어 “Let’s go!”를 스페인어 “Vamos!”로 번역하는 과정을 예시로 들고 있다.
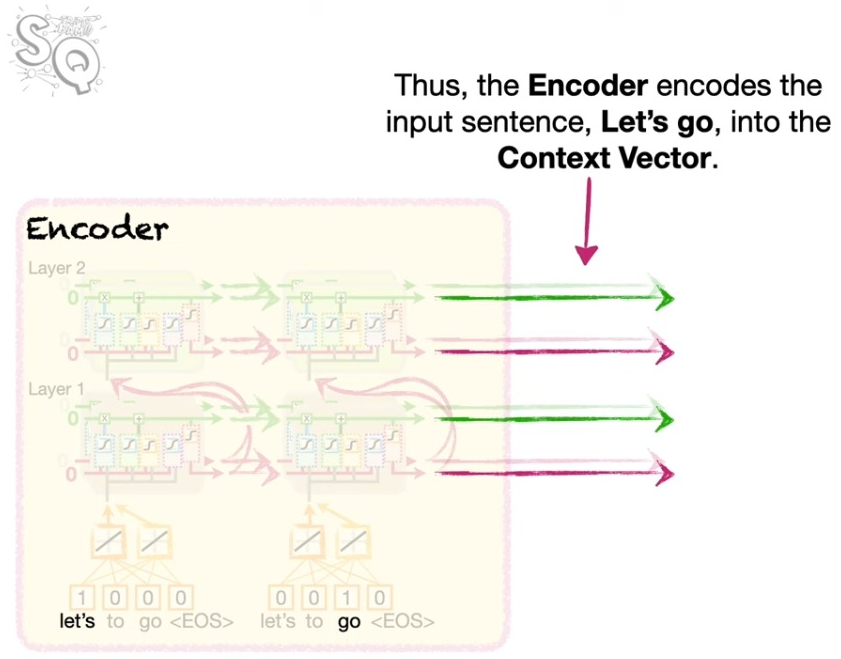
Context Vector
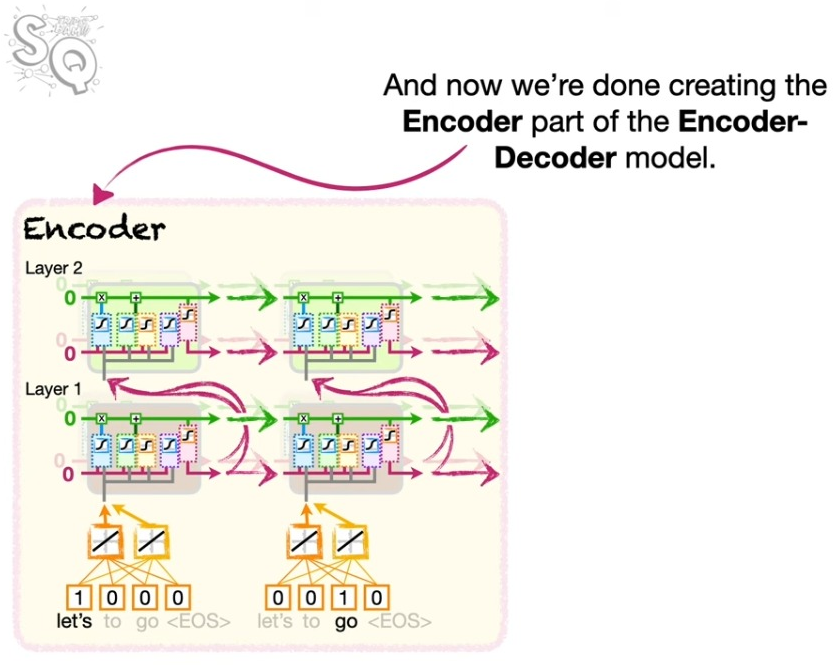
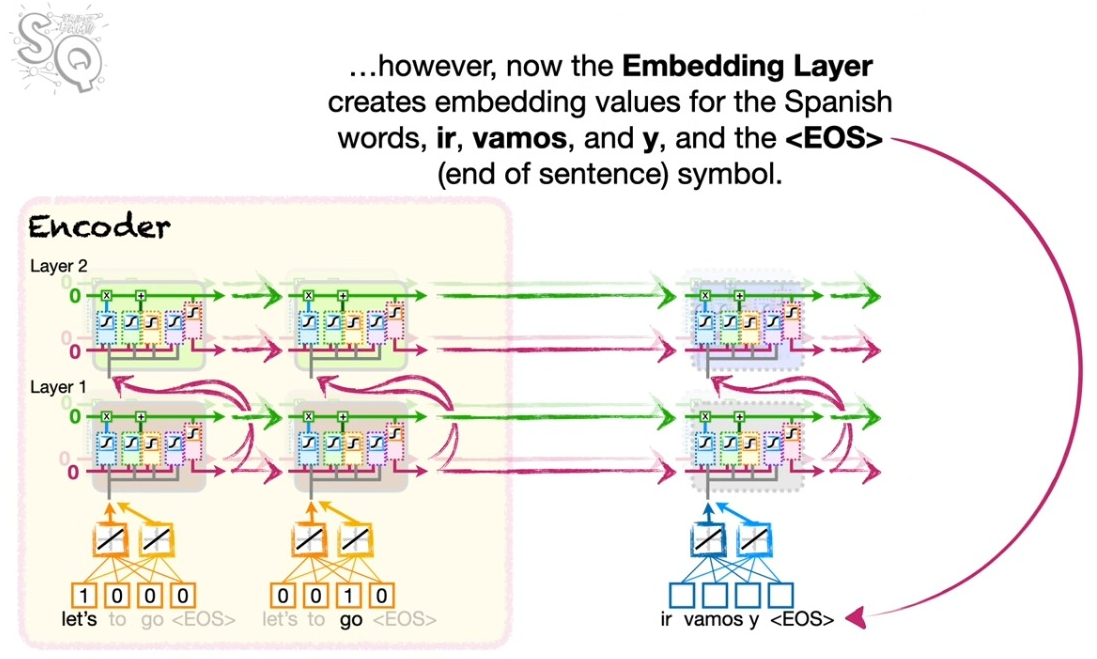
인코딩 파트의 그림을 잘 보자. 몇 가지 요소들을 확인할 수 있다.
- 맨 아래 워드 임베딩이 포함되어 있음을 알 수 있다. 이는 언어를 숫자로 바꾸는 과정이다.
- LSTM은 두 개의 레이어로 이루어져 있고, 각 레이어의 셀(노드)은 2개로 구성되어 있다.
이렇게 인코딩을 통해 만들어진 정보를 컨텍스트 벡터라고 부른다. 이 녀석을 활용해서 디코더에 초깃값을 부여한다.
Decoder
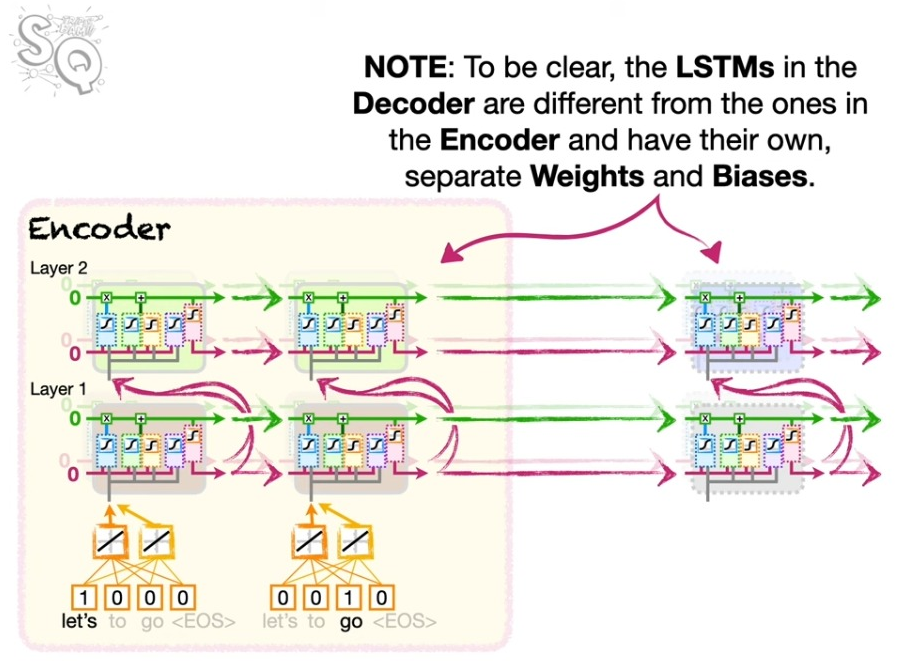
Word Embedding for Encoder and Decoder
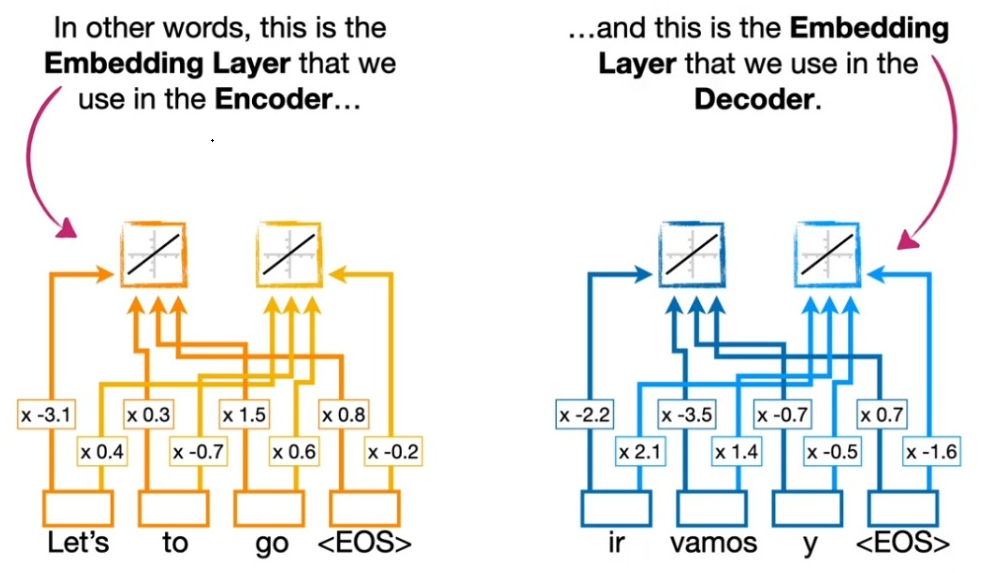
인코딩과 디코딩이라고 생각하면 각각 인코딩에서 인풋을 디코딩에서 아웃풋을 처리하는 이미지를 떠올릴 수 있다. 하지만 ’번역’의 맥락에서 인코딩은 인코딩되는 세계의 단어의 정보를 압축하는 것이고 디코딩이란 이 정보에 기반해서 디코딩 세계의 단어의 정보로 풀어내는 것을 의미한다. 따라서 인코딩과 디코딩 각각에 대해서 워드 임베딩이 필요하고, 물론 각각의 웨이트와 바이어스 역시 다르다.
Word Unembedding?
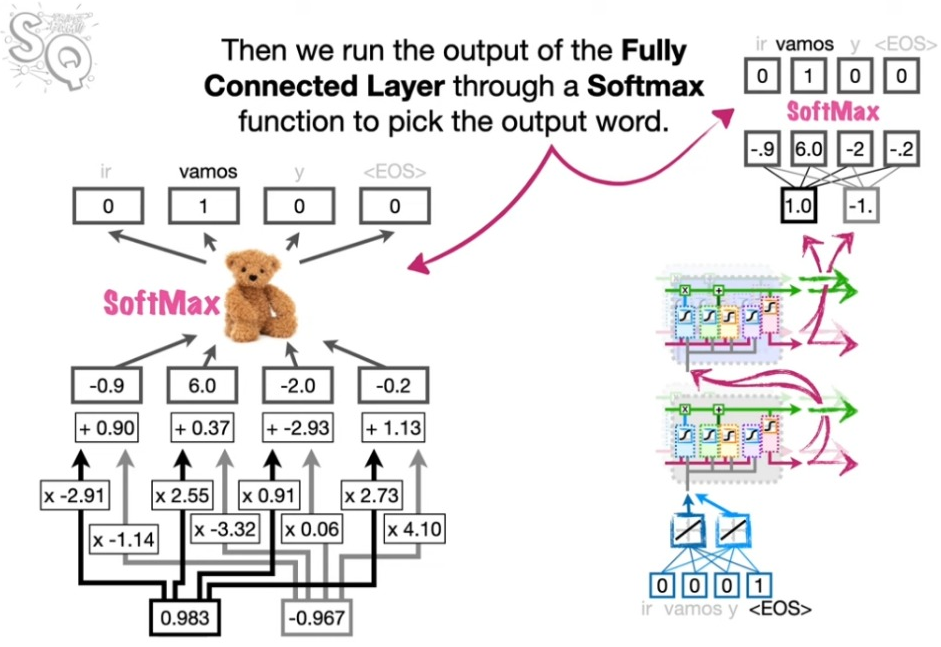
디코더의 끝단에에서는 디코딩된 정보를 다시 말로 풀어주는 과정이 필요하다. 이는 워드 ㅇㅁ베딩의 역과정이라고 생각하면 된다.
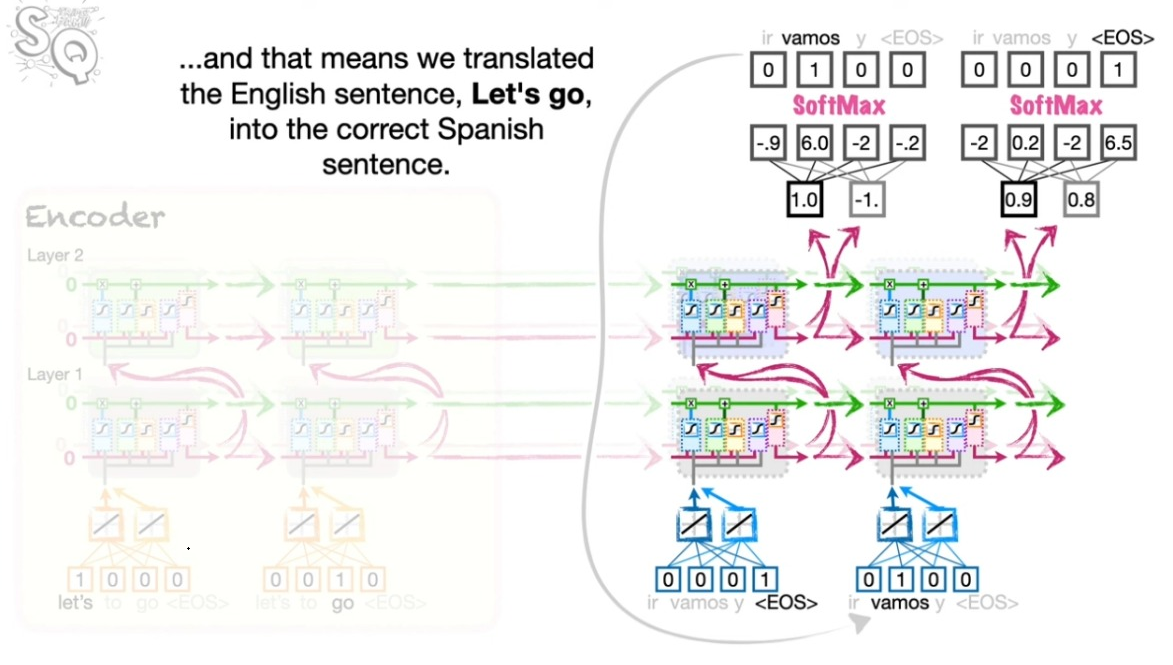
<EOS> 사용하기
디코딩에서는 <EOS>를 먼저 넣는다. 그리고 디코딩 프로세스는 <EOS>가 나올 때까지 계속한다.
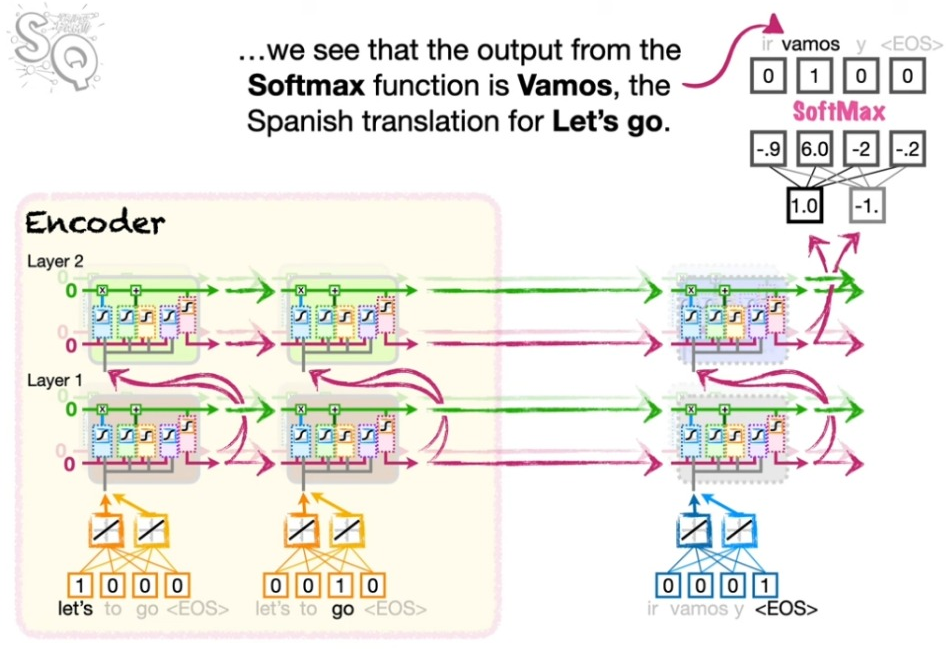
<EOS>에서 시작!
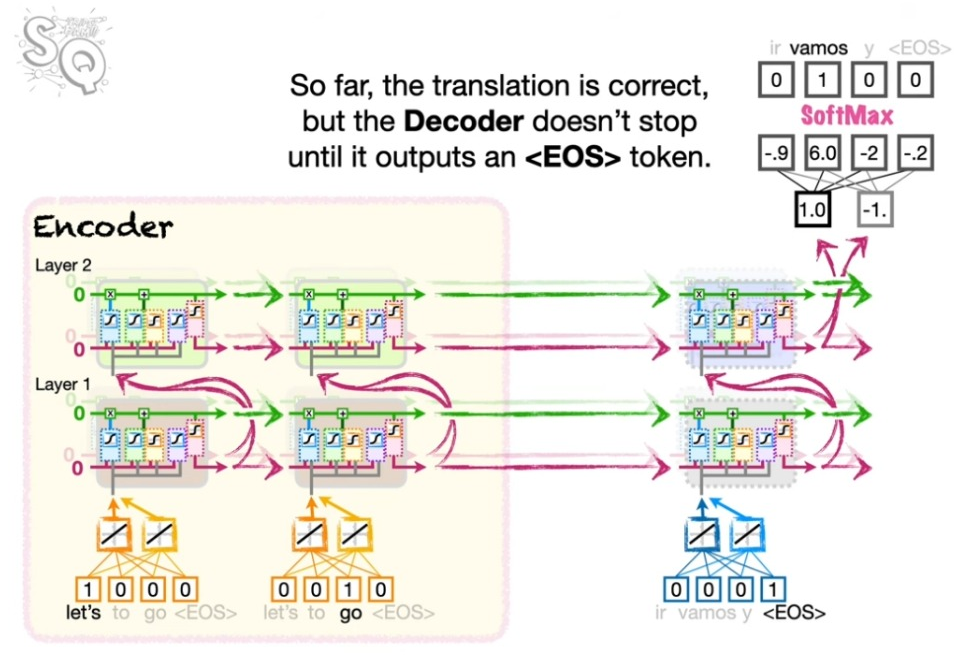
<EOS>가 풀려 나올 때까지