Transformer
TL; DR
Transformer를 급히 찍먹한다.
인풋과 아웃풋의 크기가 다를 때
RNN은 CNN과 달리
Four Key Components
트랜스포머는 크게 4가지의 구성요소로 이루어져 있다.
- Positional Encoding
- Self-Attention Mechanism
- Encoder
- Decoder
Positional Encoding
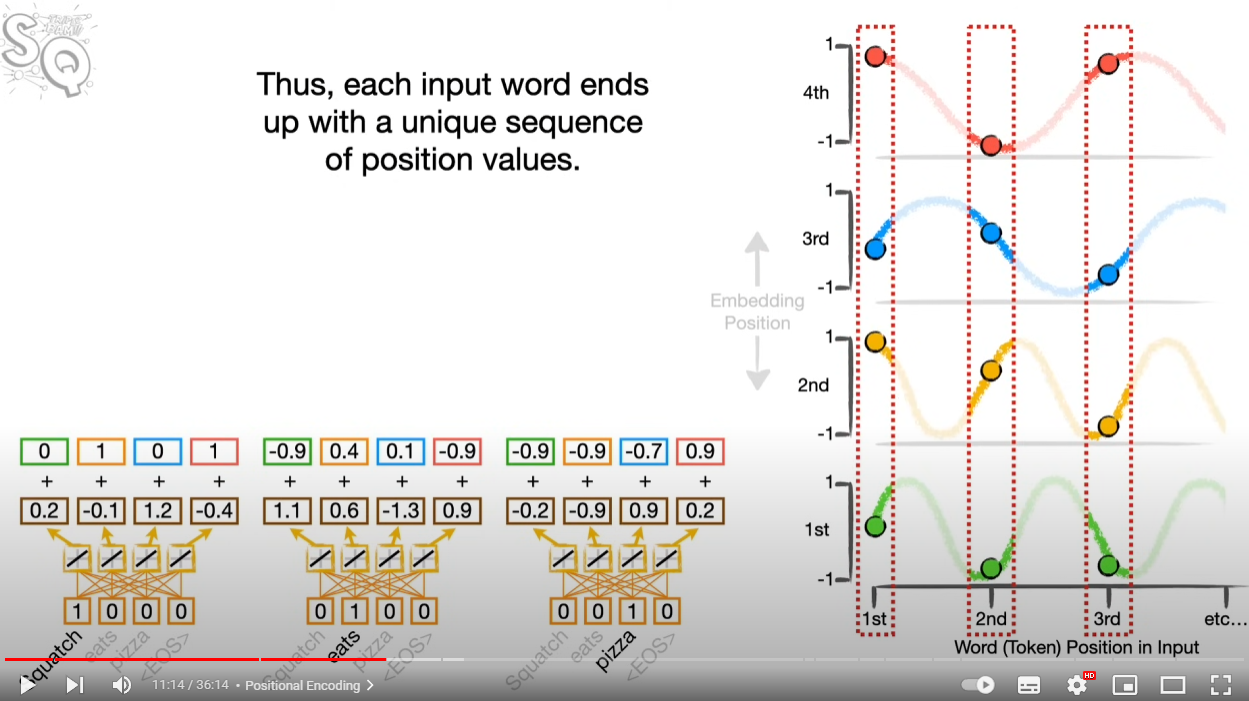
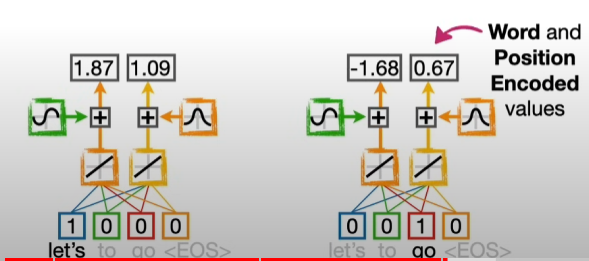
단어의 위치를 인코딩하는 방법이다. 여러가지 방법이 있지만 사인-코사인 커브를 사용하는 것이 제일 일반적이라고 한다. 언뜻 보면 이해가 가지 않지만 사인 코사인의 파동 값을 활용하면 별다른 정보 손실 없이 벡터로 토큰의 위치 정보를 잘 반영할 수 있다.
Self-Attention Mechanism
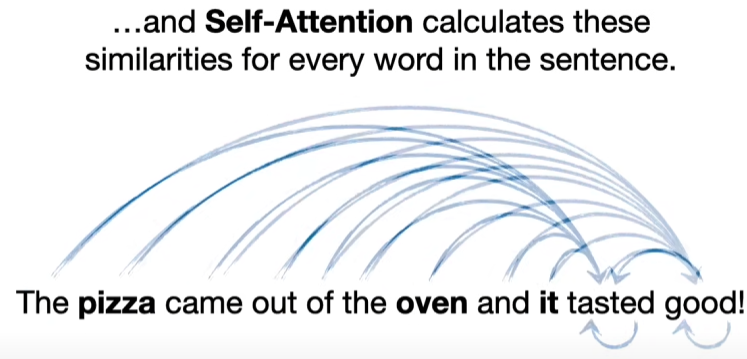
자신을 포함해서 단어 사이의 유사도를 계산한다.
세 가지 하부 요소가 있다.
- Queries: 각 단어 자체를 표현하는 뉴럴넷의 중간 결과
- Keys: 각 단어와 다른 단어를 비교할 때 활용할 뉴럴넷의 중간 결과
- Values: 각 단어의 셀프 어텐션을 거친 중요도를 표현하는 뉴럴넷의 (중간) 결과
쿼리와 키의 닷프로덕트를 구하면 스칼라 값을 얻게 된다. 이 녀석을 다시 softmax 함수에 넣어 정규화한 후 이 값을 세번째 구성요소인 Value를 거치도록 한다.
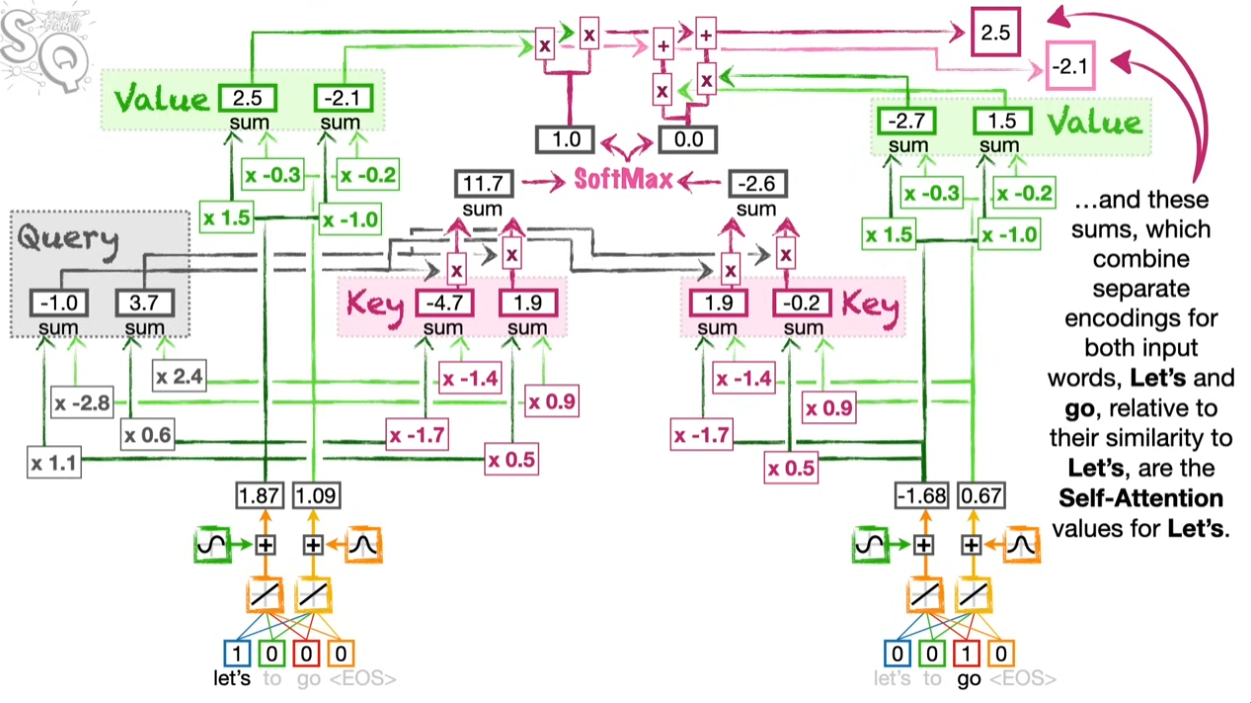
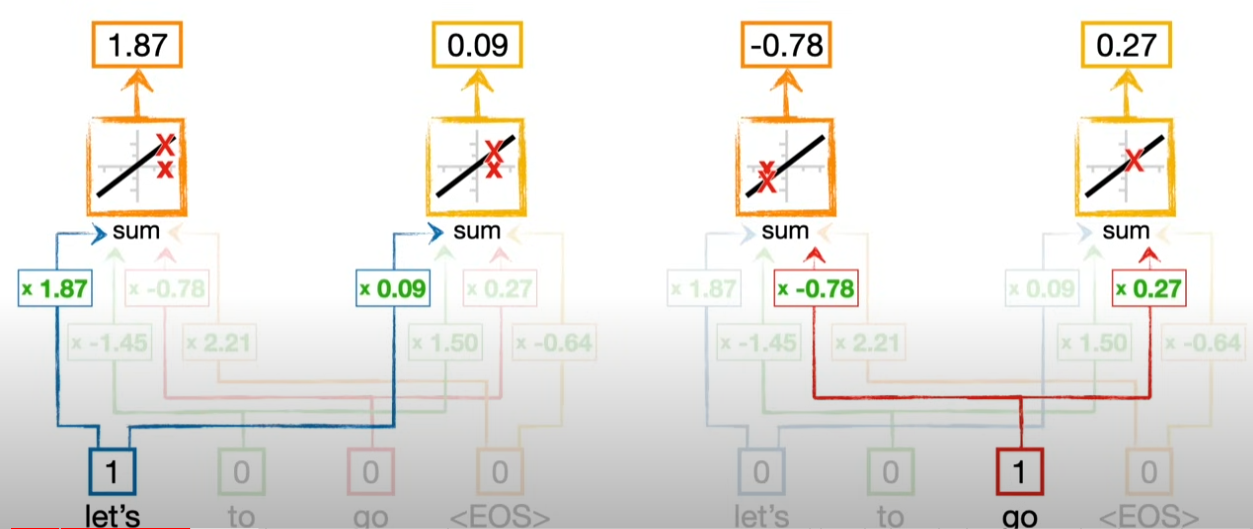
그림을 보면서 다시 한번 확인하자. 위 그림은 “let’s”가 자신 및 “go”와의 셀프 어텐션을 고려하여 Query, Key, Value를 계산하는 과정을 보여준다.
같은 방식으로 “go”에 대해서도 계산을 수행한다. 여기서 중요한 대목이 나온다. “go”에 대해서 인코딩을 할 때 Query, Key, Value의 웨이트를 “Let’s” 때 썼던 것을 그대로 활용한다. 한 문장 안에서 단어의 의미가 맺고 있는 연결망이 같다고 보면다면 재활용이 가능하다. 그리고 이 때문에 병렬화가 가능하다! 즉 RNN처럼 앞부터 순차적으로 계산할 필요성이 사라지는 것이다.
정리
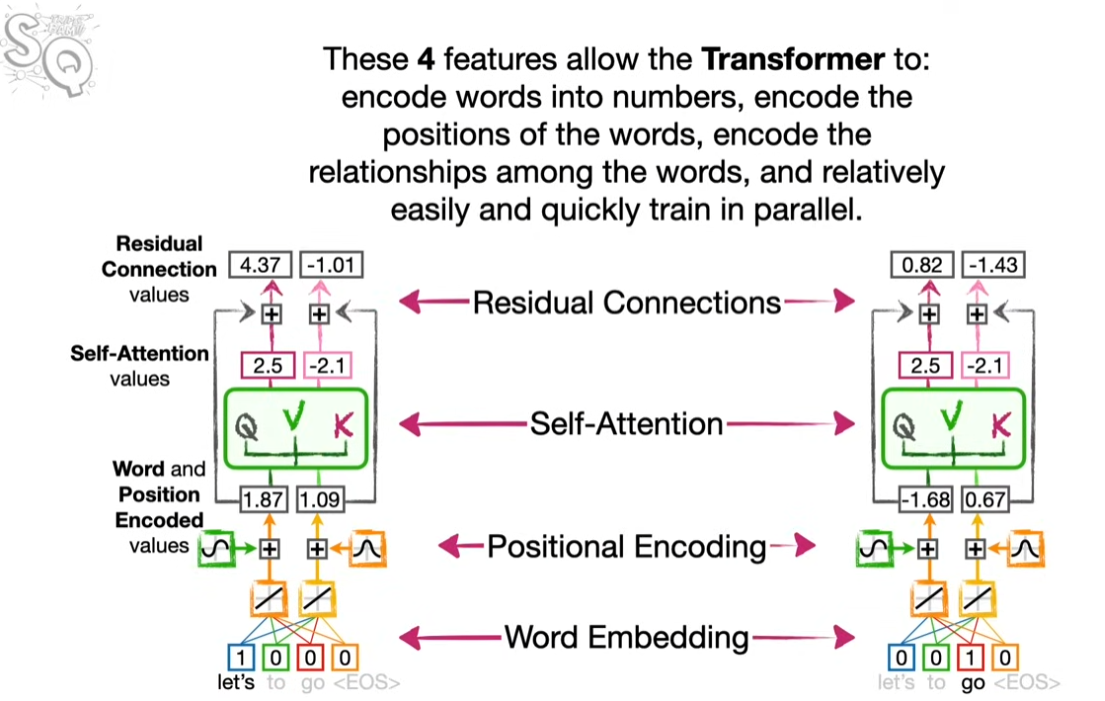
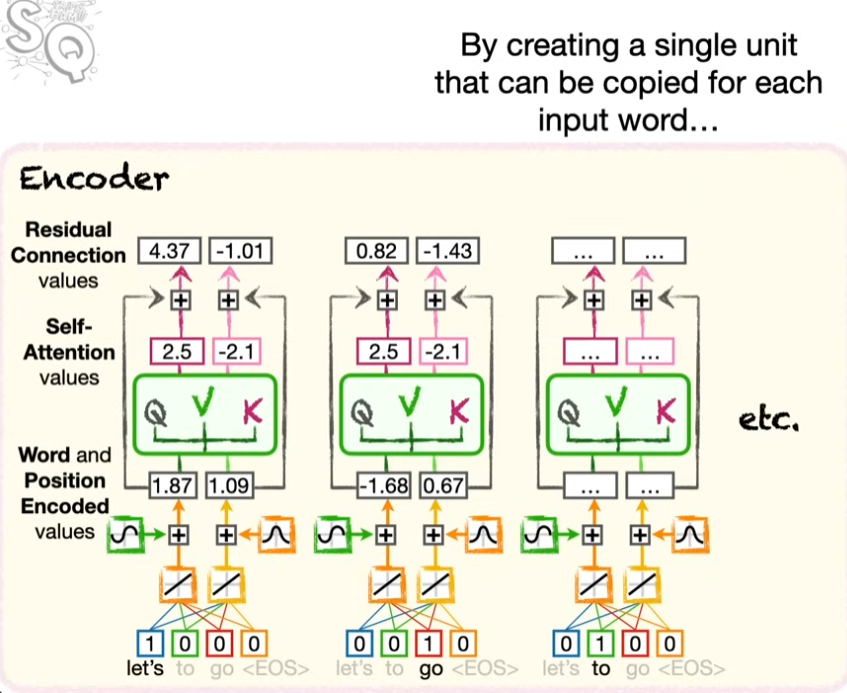
- Word Embedding: 단어를 벡터로 표현한다.
- Positional Encoding: 단어의 위치를 인코딩한다.
- Self-Attention Mechanism: 단어 사이의 유사도를 계산한다.
- Residual Connection
Decoder
강의는 영어-스페인어의 번역의 맥락을 살펴보고 있다. 따라서 스페인어의 인코딩에서 시작한다.
스페인어에 대해서 4단계의 트랜스포머 셀프-어텐션 프로세스를 마치고 어텐션 아웃풋을 얻는다. 인코딩의 과정이 기본적으로 동일하다. 다만 서로 다른 구조(언어)의 문장이므로 각 단계에 활용되는 웨이트는 다르다.
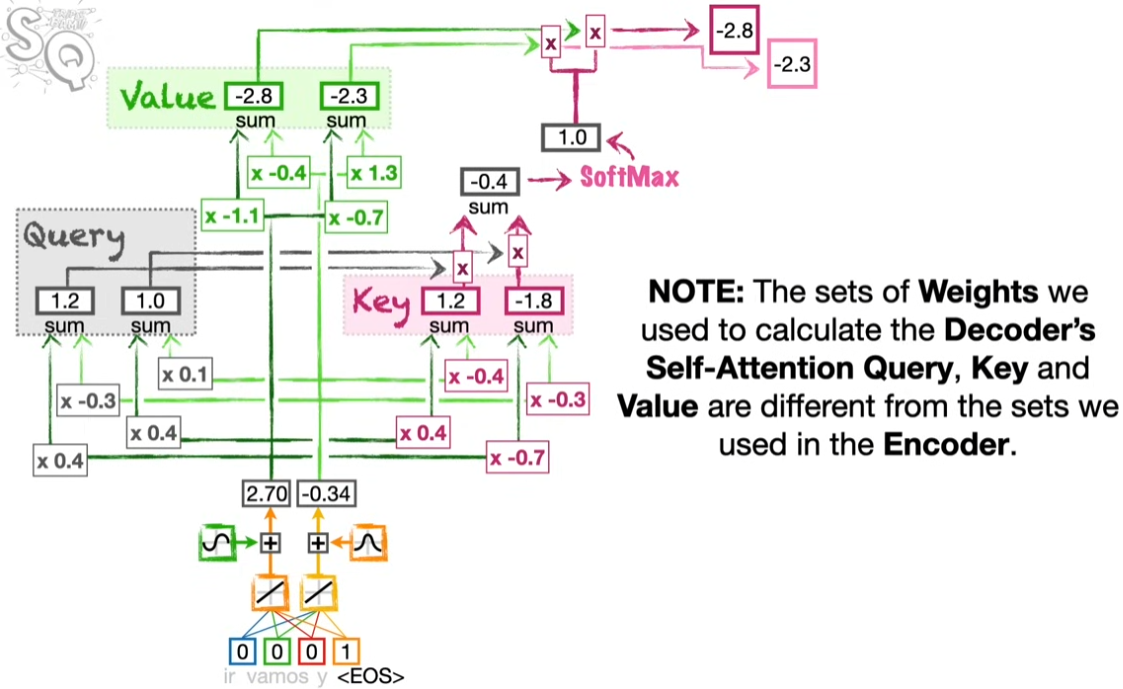
Encoder-Decoder Attention
이제 이 두 개의 어텐션을 엮을 차례다. 어텐션 밸류가 생성된 디코더를 쿼리 자리에 넣고 인코더의 키를 활용해서 결과를 얻는다.
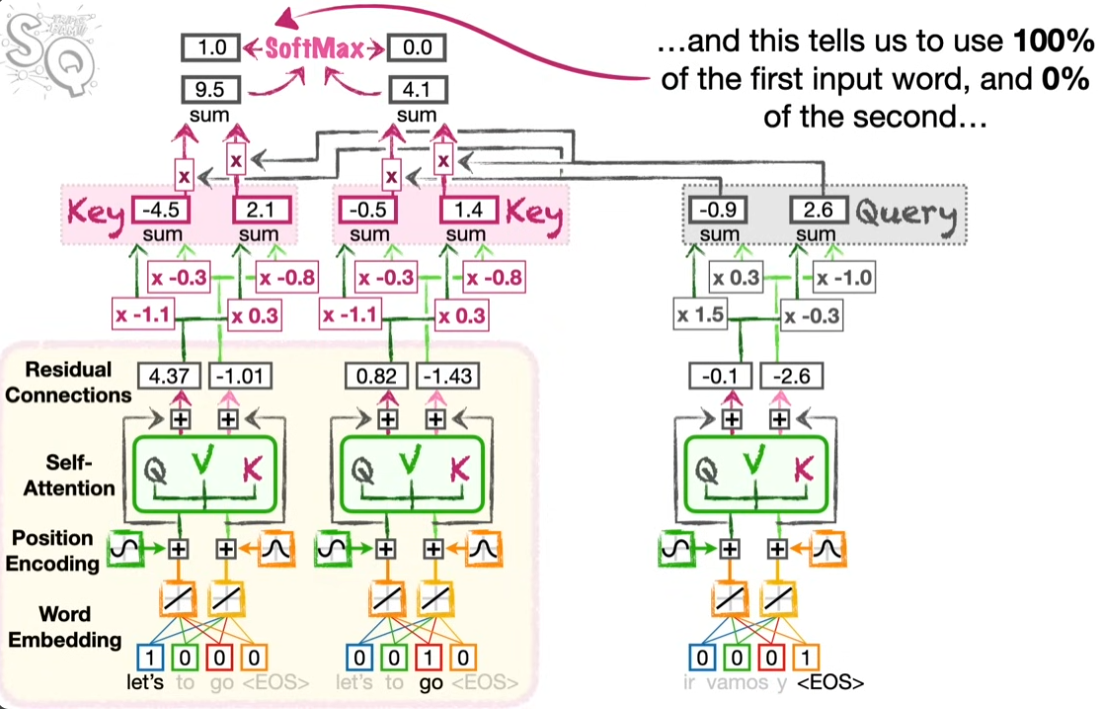
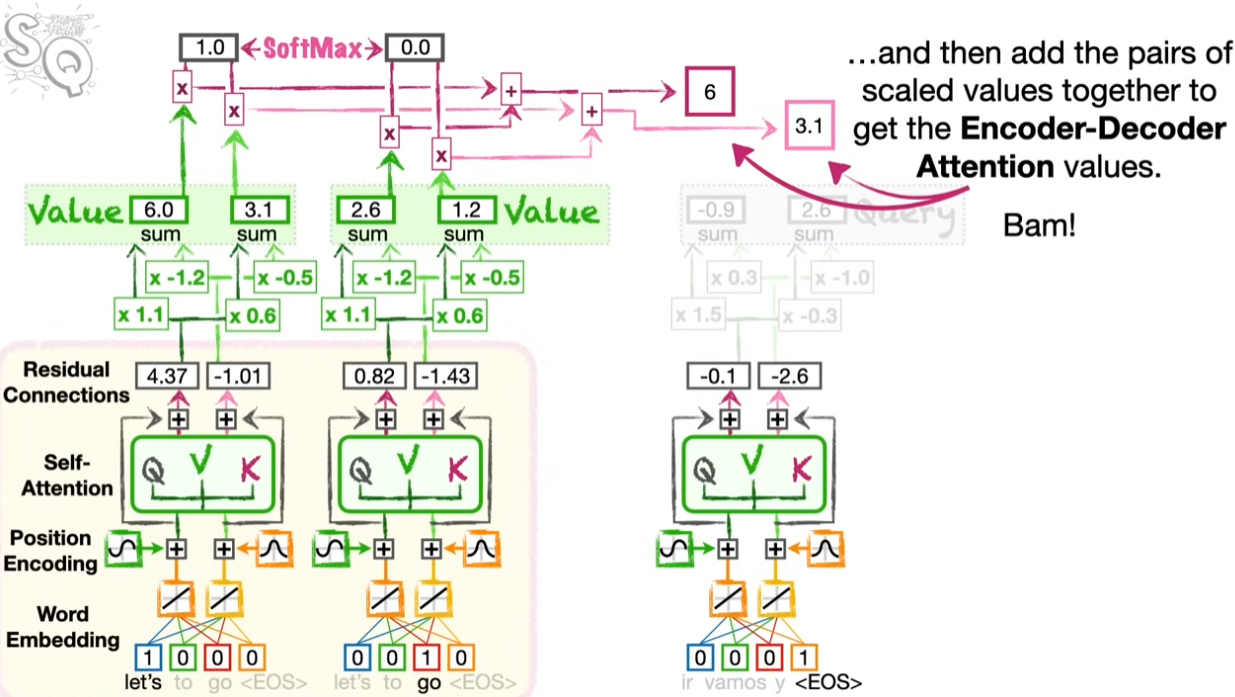
인코더-디코더 어텐션의 아웃풋이 생성되고 난 후 마지막에 뉴럴넷을 통해서 스페인어 아웃풋을 산출한다. <EOS>(End of Sentence)까지 투입을 마치면 한 문장에 관한 번역이 완료된다.
Comments
멀티-헤드 어텐션은 같은 단어가 여러 개의 의미를 지니는 경우를 위해 필요하다. 몇 개를 설정해야 하는지는 흑마술이다. 원활한 학습을 도모하기 위해서 워드 임베딩과 포지셔널 임베딩의 벡터를 더하는 것이 residual connection의 역할이다.
만일 셀프 어텐션에서 같은 언어끼리라도 문장에서 서로 다른 의미망을 지닐 수 있다면 여러 개의 어텐션 유닛이 필요할 것이다. 이를 multi-head attention이라고 한다.