Busy Person’s Intro to LLMs
TL; DR
LLMs에 관해 안드레이 카파시의 흥미로운 견해를 정리해보자.
넋두리
LLMs를 이해하는 방법은 다양하다. 많이 알수록 더 간결하고 적확한 표현을 구사할 수 있다고들 하는데, 카파시의 경우가 그러했다. 인상적인 대목들 몇 가지 정리해 보자.
Ted Chiang, “A Blurry JPEG of the Web”

테드 창은 chatGPT란 결국 웹의 부정확한 혹은 흐릿한 압축 버전의 무엇에 지나지 않는다는 뜻으로 이 표현을 사용했다. 이 표현이 부정적인 뉘앙스를 지니고 있지만 LLMs에 관한 논의의 좋은 출발점을 제공한다.
그래서 LLMs을 의심해야 할까? 그렇다. 그리고 거부해야 할까? LLM을 그냥 적당한 사람으로 대체해보자. LLM 정도로 일을 하는 사람을 우리가 “천재”라고 부르지는 않겠지만 그럭저럭 일 잘하는 사람 정도로는 인정할 수 있을 것이다. 적당한 수준에서 잘하는 것을 blurry라고 표현한다면, 그리 부정적인 것은 아닐 수도 있겠다.
카파시의 LLMs 이해 역시 비슷하다.

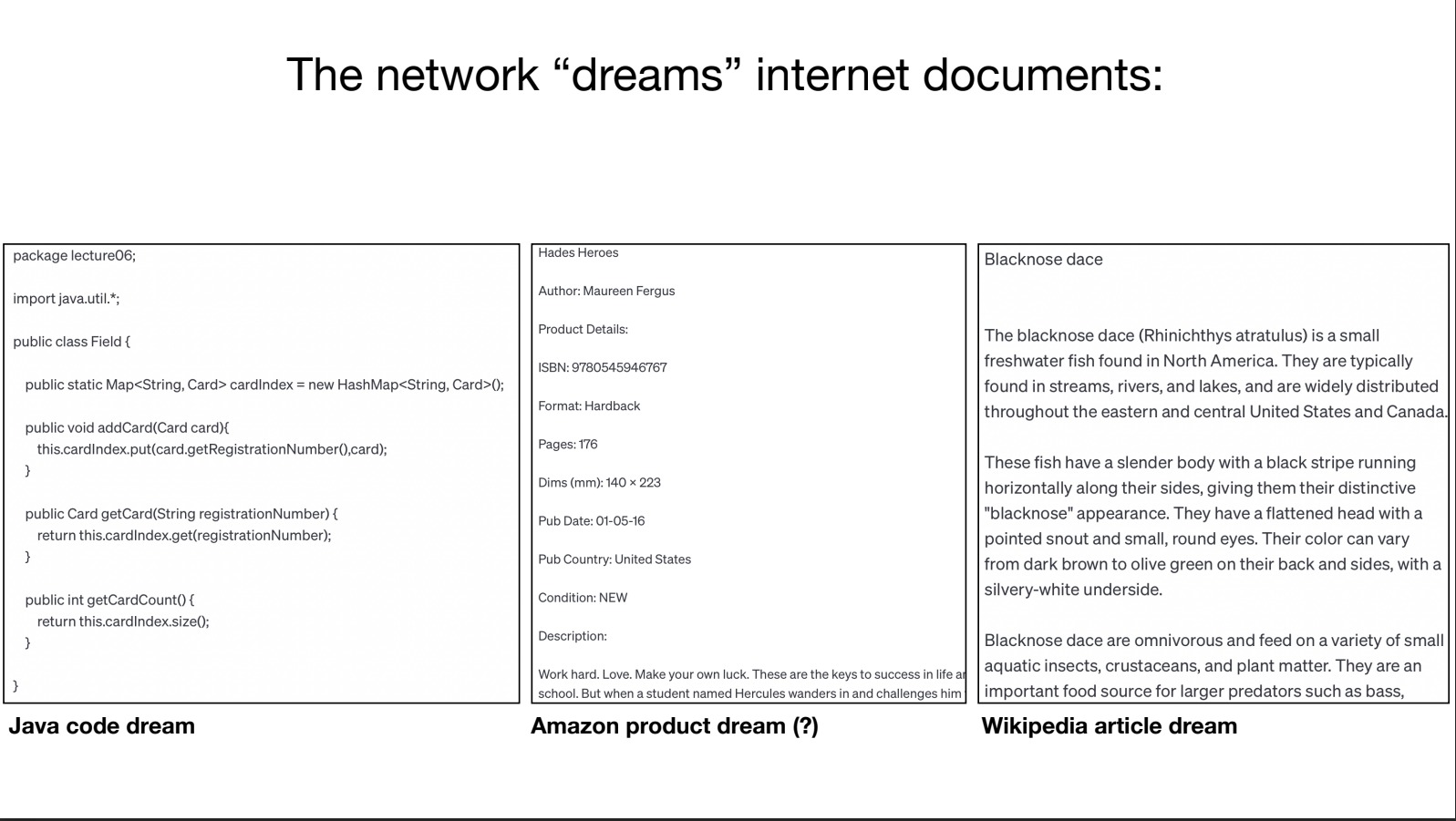
상당 기간 동안 검색을 사용해서 이에 익숙해진 어떤 사람이 있다고 하자. 그가 검색을 통해 알게 된 지식이 모두 맞는 것은 아닐 터다. 하지만 확률적으로 다른 보통의 사람보다 그가 낫다면 그의 쓸모는 충분하다. 컴퓨터가 내놓는 무엇이 언제나 정확하리라는 인간적인 편견을 잠시 치우고 생각하면, 사람이 아닌 이런 존재가 있다면 꽤 활용도가 높지 않을까?
뉴럴넷은 인터넷 문서를 “꿈꾼다.” LLMs에서 생성이라는 말은 사실 “꿈꾸는” 것에 가깝다. “꿈꾼다”라는 표현이 찰지면서도 정확하다. 엄밀히 말하면 뉴럴넷은 문서를 쓰지 않는다. 꿈꾼다. 여느 인간의 꿈처럼 헛소리가 들어갈수도 있고, 정확하지 않을 수도 있다. 하지만 인간에게도 그러하듯이 꿈꾸는 것, 백지 위에 무엇인가를 그려내는 것이란 쉽지 않은 일이다.
Human Feedbacks


뉴럴넷은 인간이 원하는대로 움직이지 않는다. 그 내부의 작동 원리를 온전하게 모른다는 점에서 뉴럴넷은 그 발상을 복제한 인간의 뇌와 꽤 비슷하다. 인간의 아이를 학습시키는 과정을 떠올려보자. 뭔가 가르치고 싶은 것이 있다면 부모가 해당 내용을 밖에서 계속해서 주입한다. 이 작업이 뉴럴넷에 인간의 손길을 더해주는, 즉 양육의 과정이다.
카파시는 크게 두 가지를 제시한다. 하나는 ’보조 모델(assistant model)’을 인간이 만들고 이 내용을 뉴럴넷 안에 바꿔 끼워넣는 것이다. 두번째는 LLMs가 꿈꾼 여러 답들을 인간이 비교해서 더 나아보이는 것을 알려주는 것이다.
첫번째 과정이 프리트레인 모델을 얻는 과정이라면 두 번째가 이른바 미세 조정(fine-tuning)이다. 첫번째가 거의 순수한 엔지니어링의 영역이라면 두번째는 ‘소셜’ 엔지니어링의 영역이다. 오늘날 chatGPT의 성공에는 GPU를 활용한 대규모 학습을 가능하게 한 첫번째 영역의 공로 만큼 두 번째 영역의 공로도 크다. 어쩌면 미세 조정의 영역이 각 모델을 내놓는 회사들의 숨은 역량이 발휘되는 곳일지도 모른다.

System I and II for LLMs?
카파시는 인공 지능의 미래에 관해서 여러가지 언급을 하고 있다. 다양한 입력 형태(멀티모달)을 받을 수 있게 진화하고 있으며 이는 가속될 것, 그리고 마지막에 꽤 길게 LLMs 보안에 관해 논하고 있다. 보안에 관한 내용이 흥미롭기는 하다. LLM을 해킹하는 방법은 기술적인 것을 뛰어넘는다. 마치 해커들이 서버나 서비스를 해킹할 때 순수한 네트워크 기술 넘머의 소셜 엔지니어링을 활용한 것과 유사하다.
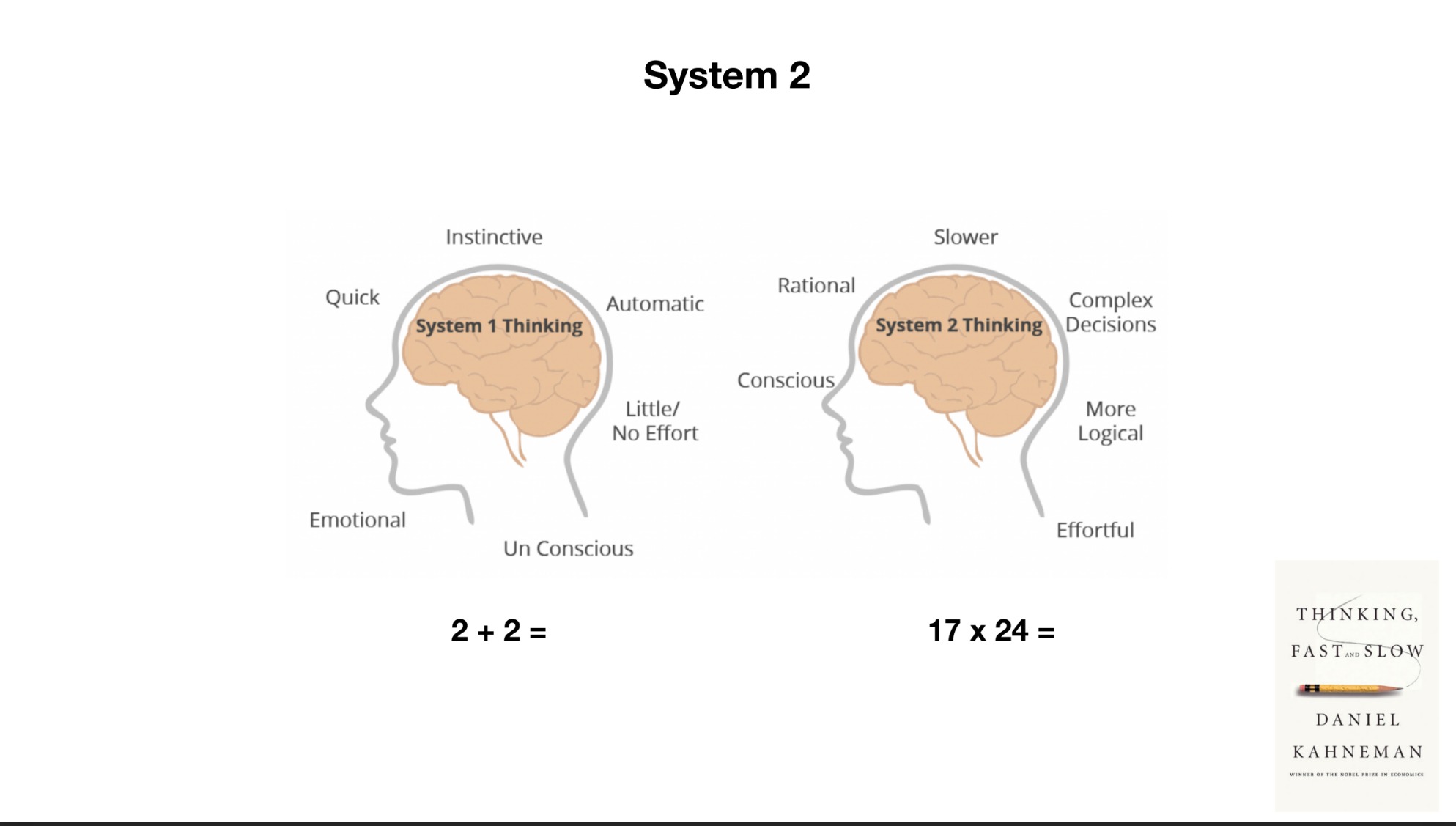
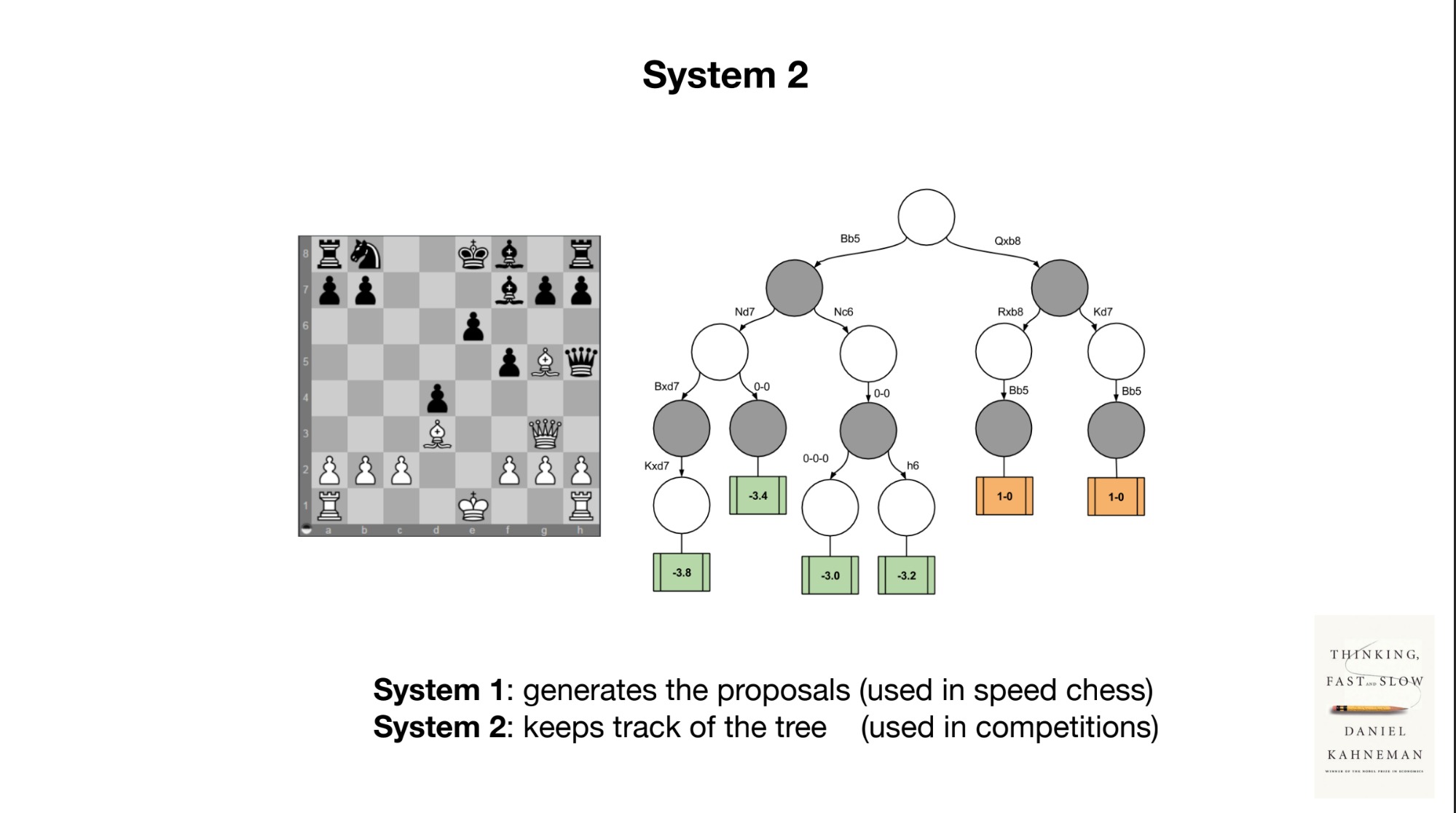
무튼 미래에 관한 논의에서 내가 제일 놀란 것은 것은 시스템1, 시스템2에 관한 언급이다. 시스템1, 시스템2는 다니엘 카너만의 책에서 나온 개념이다. 시스템1은 빠르고 직관적인 판단을 내리는 것이고 시스템2는 느리고 논리적인 판단을 내리는 것이다. 카파시는 LLM이 시스템1이라고 말했다.
인공지능이 시스템1이라고? 디지털을 통해 산출된 결과물이 시스템1이라는 발상은 언뜻 와닿지 않지만, 생각해보면 이 말이 맞다! 앞서 LLMs가 꿈꾸는 것이라고 했는데, 꿈은 시스템1의 영역이다. 시스템2는 논리적인 추론을 하는 영역이다. LLMs가 시스템1이라면, LLMs와 어울리는 시스템2는 무엇일까? 아직 미지의 영역이다. 컴퓨팅 자원을 더 소모하고 결과를 얻는데 더 시간이 걸리더라도 이 개념이 만들어지면 LLMs에 또다른 도약이 있지 않을까 한다.

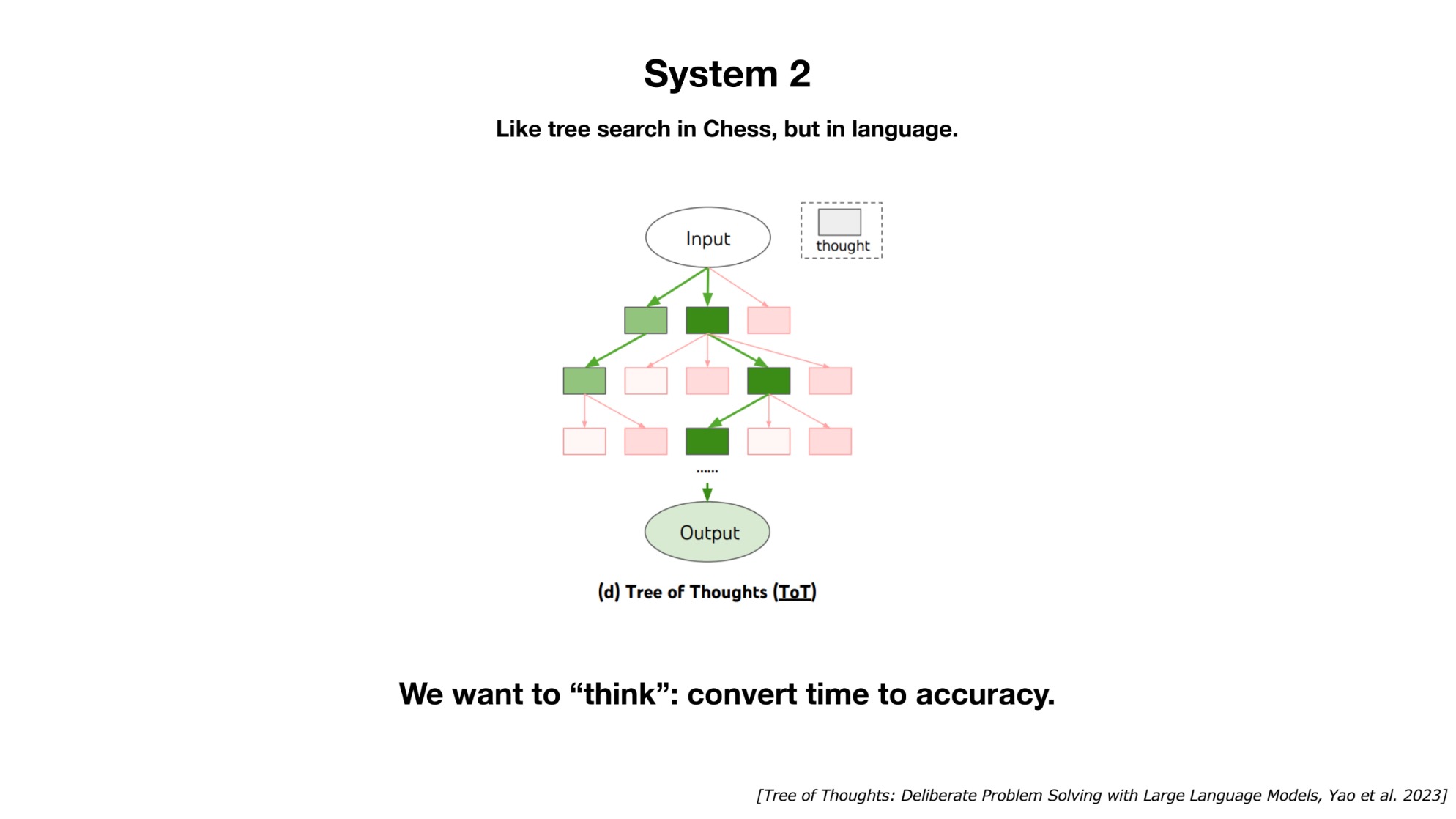
시스템2를 갖춘 LLM이 있다면 맞든 틀리든 녀석의 인과적인 추론의 과정을 뜯어볼 수 있었을 것이다. 이게 가능했다면 보다 정확하고 처방적인 대응을 내놓는 LLM을 만들어 낼 수 있지 않을까?
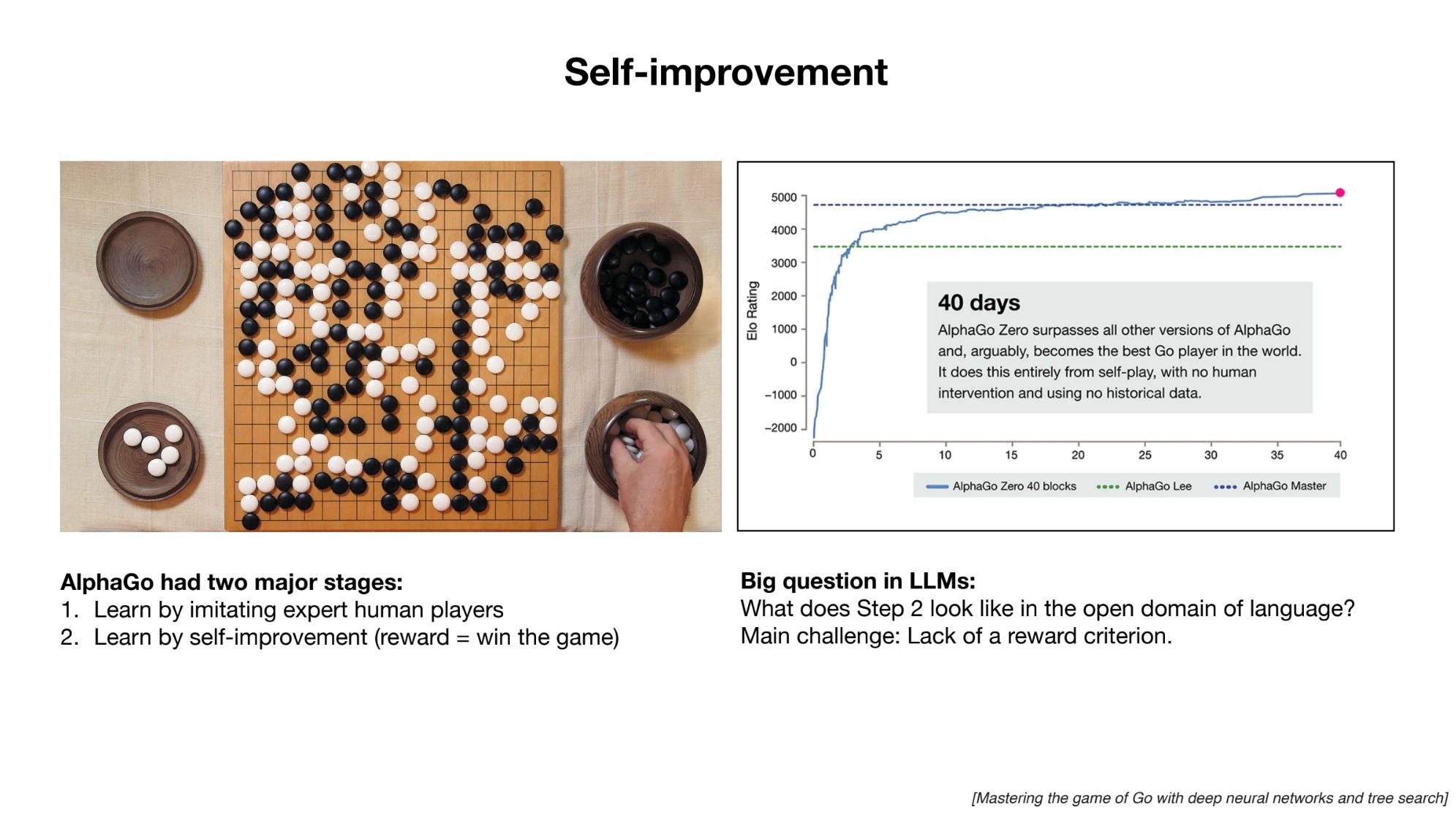
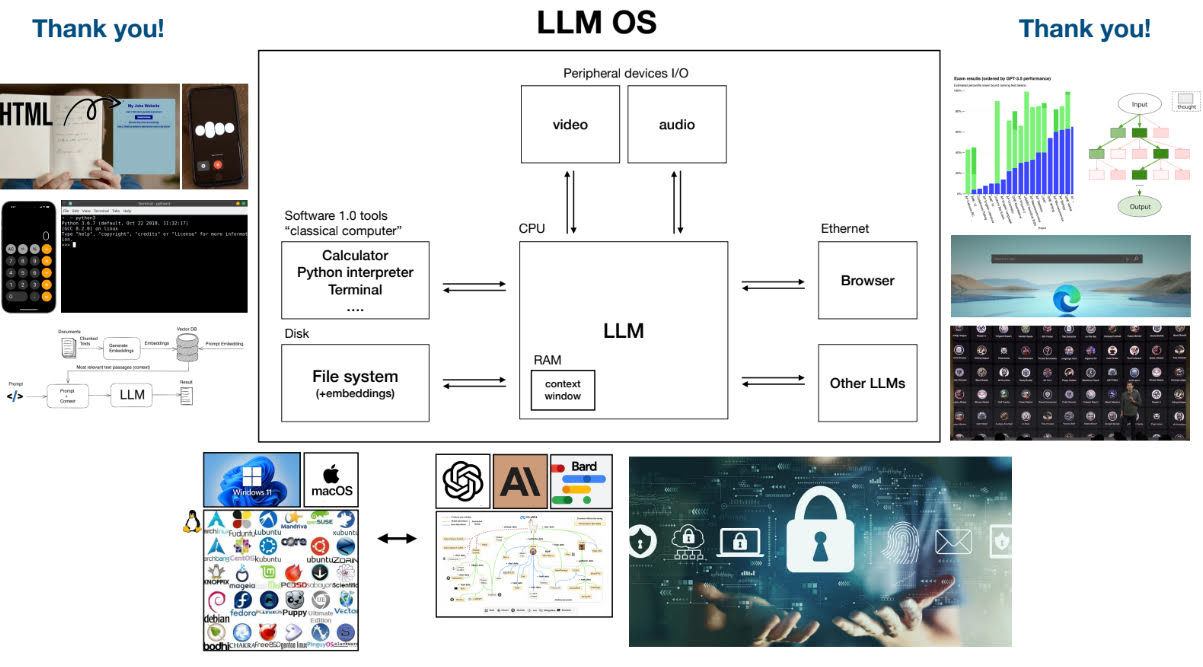
이외에 인간 기보에서 배운 초기 알파고 이후에 등장한 스스로 배우는 알파고에 해당하는 LLM 모델에 관한 질문, LLM 중심의 OS 등 흥미로운 슬라이드 샷을 몇 개 덧붙이겠다.