Word2Vec
TL; DR
w2v의 기본 아이디어 위주로 정리해 보자.
넋두리
이른바 NLP의 주요한 돌파구가 된 것이 w2v의 아이디어다. 요즘 유행하는 트랜스포머 알고리즘 또한 그 시작은 w2v에 있다. 원래의 w2v의 형태로 실전에 활용되는 경우는 거의 없겠지만, 그 기본 아이디어는 여전히 새겨볼 만하다.
Word to Vector
컴퓨터는 당연히 사람의 언어를 ‘그대로’ 알아들을 수 없다. 컴퓨터가 언어를 이해하기 위해서는 언어를 먼저 숫자로 바꿔야 한다. 이렇게 말(단어, 문장, 문단)을 숫자로 바꾸는 작업이 w2v의 거의 전부이다.

중요한 것은 ‘어떻게’ 바꾸는지에 있다. 우선 강의 슬라이드에 나온 대로 “Troll 2”, “is”, “great”, “Gymkata” 네 개의 단어를 생각해 보자.
가장 쉬운 방법은 해당 단어들에 임의로 숫자를 부여하는 것이다. 이렇게 숫자를 부여하면 컴퓨터에 넣을 수는 있다. 다만 이렇게 부여된 숫자가 의미 있는 정보일까? 아니다. 인간의 언어가 지닌 ’의미’를 되도록 가깝게 컴퓨터로 옮기려면 말이 지니는 관계 혹은 말 사이의 연결망까지 모두 숫자에 반영되어야 한다.
- 왜 word to number가 아니라, vector일지 먼저 따져보자. 인간의 언어는 하나의 의미만 지니지 않고 다양한 의미를 지니고 있다. 이를 반영하기 위해서는 스칼라 숫자 하나로는 부족할 것이다. 벡터의 등장은 이런 점에서 타당하다.
- 다음으로는 비슷한 의미를 지니는 말들이 서로 비슷한 값을 지니면 좋을 것이다. 언어의 원래 의미가 벡터에도 잘 반영되어야 한다는 뜻이다. 스칼라 값이 아니므로 벡터 사이의 유사도 즉 코사인 유사도 등을 활용하면 되겠다.
Neural Net
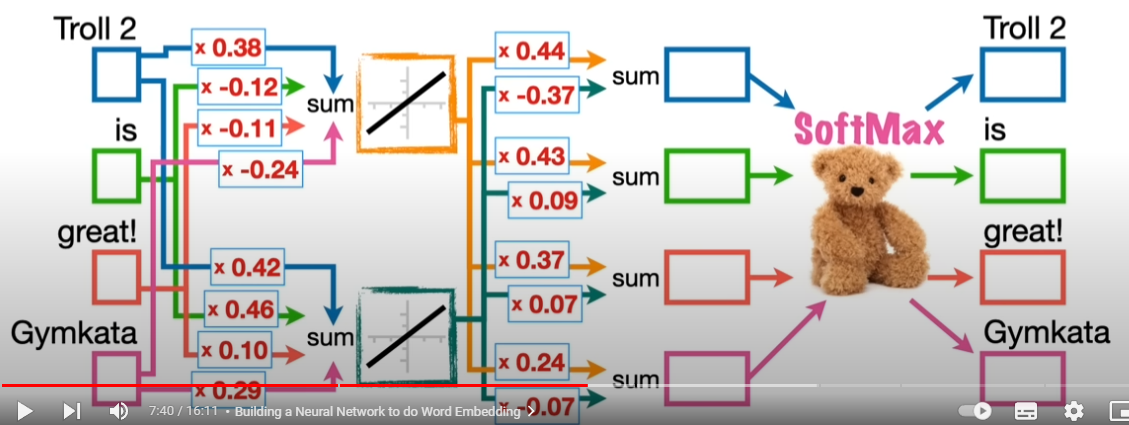
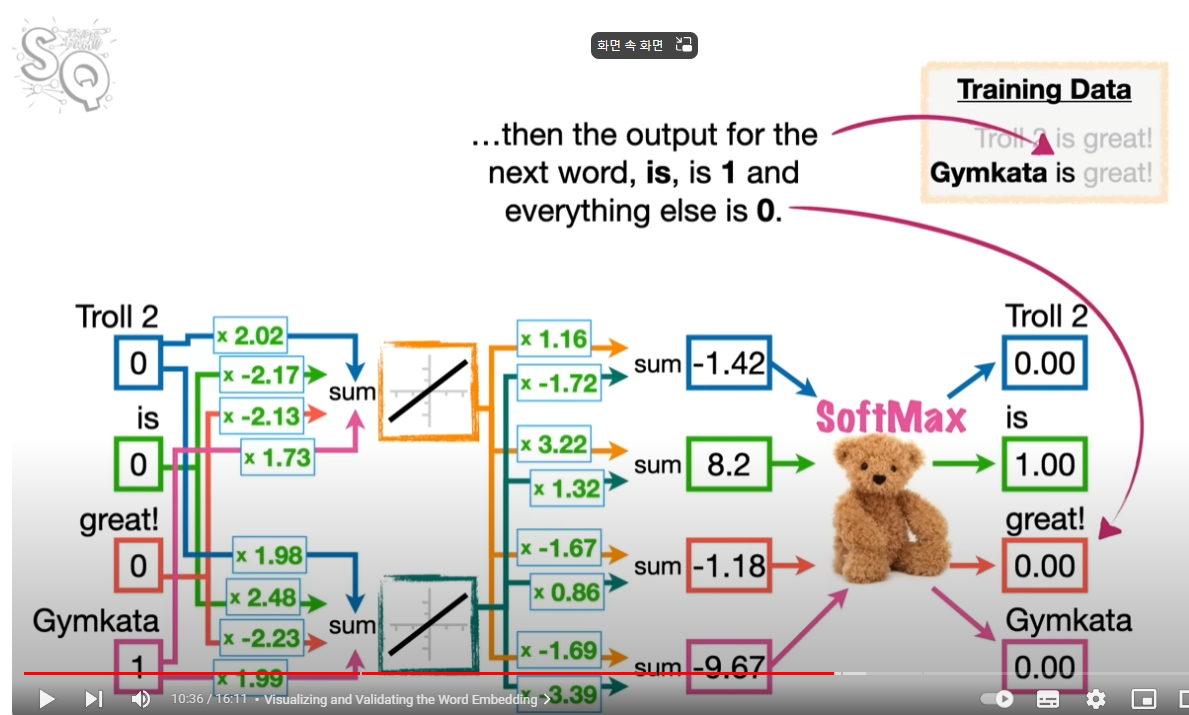
신경망의 투입이 예측(뒤에 나올 단어)을 잘 맞출 수 있도록 네트워크의 웨이트와 바이어스를 조율해나간다
이제 신경망을 구성해서 학습을 시킬 차례다. 투입은 당연히 각 단어의 벡터이다. 해당 단어만을 1로 처리하고 나머지를 0으로 둔다. 산출 즉 아웃풋은 뒤에 나올 단어의 예측치가 된다. 이 뉴럴넷을 학습시킬 때 좋은 결과란 뒤에 나올 말을 잘 맞추는 것이다.
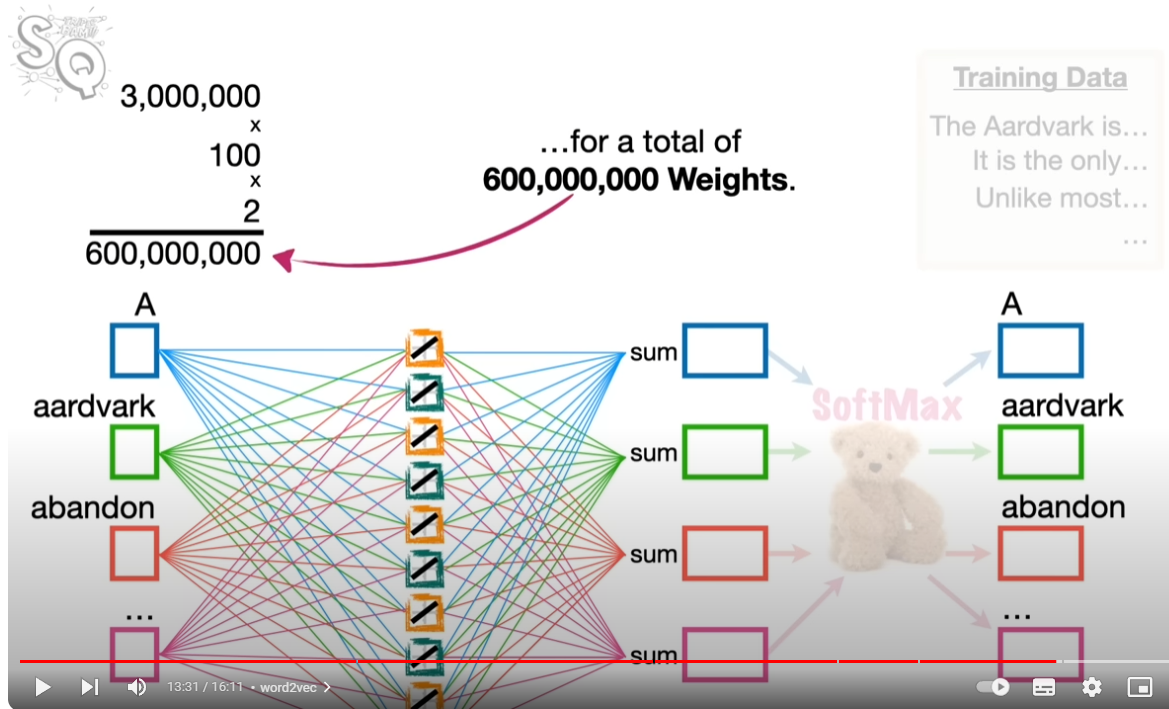
물론 실전 뉴럴넷의 파라미터 차원이 훨씬 복잡하다. 그림에서 보듯이 학습에 단어 3백만 개와 100개의 액티베이션 펑션이 있다고 하자. 아래 그림에 보듯이, 3백만 X 100 X 2 해서 6억 개의 웨이트가 필요하다.
Negative Sampling
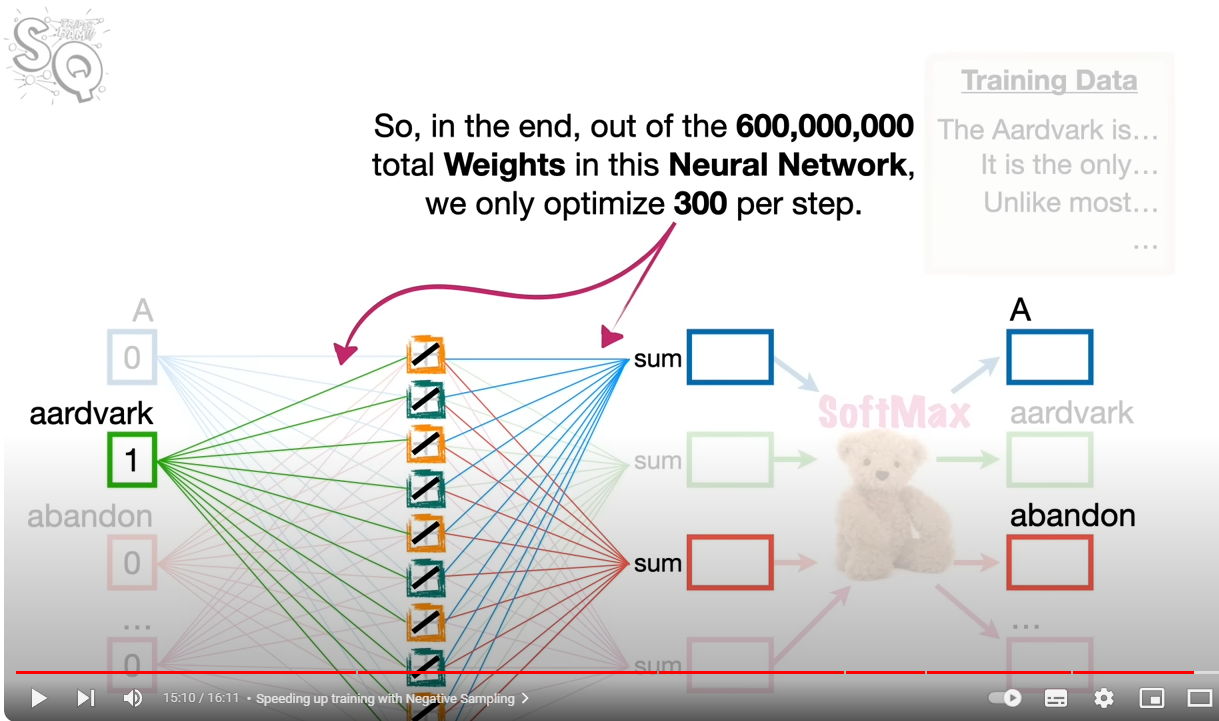
“A”를 예측하기 위해서 “aardvark”, “abandon”만을 남긴다. 산출에서 “aardvark”도 고려하지 않아도 된다. 이렇게 하면 학습해야 할 웨이트의 수가 300개로 줄어든다.
이 녀석들을 한방에 학습시키려면 너무 오랜 시간과 자원이 소모될 것이다. 그래서 조금 꼼수를 고안해볼 수 있을 것이다. 특정 단어를 예측하는데 필요한 단어를 임의로 선택하고 이 녀석의 연결망만 학습시키는 것이다. 이를 negative sampling이라고 한다.