p값? 너무 믿지 마세요
TL; DR
p값에 너무 의지하면 분석의 취지가 망가진다.
조건부 확률을 생각하라!
p값을 이해할 때 가장 먼저 떠올려야 하는 것은 조건부 확률이다. 조건부 확률에서
\[ P(A|B) \neq P(B|A) \]
이다. \(P(\text{E}|H_0)\)을 생각해보자. \(H_0\)이 영가설(null hypothesis)이다. E는 증거를 뜻한다. 즉, 관측값이다. 우리가 아는 p값이란 영가설이 맞다고 가정할 때 E라는 증거를 관측할 확률이다. 이는 당연히 \(P(H_0|\text{E})\)와는 다르다.
“P의 비극”은 이 둘을 혼동하는 데에서 시작한다.
An example


이 사례는 여기에서 가져왔다. 보다 익살스러운 사례로 xkcd 882: Significant도 참고하자.
D&D라는 게임은 다각 20면을 지닌 주사위를 쓴다. 만일 “녹색 모자를 쓰고 주사위를 던질 때 20이 더 잘나온다”는 대립가설(alternative hypothesis)을 세웠다고 하자. 이때 영가설은 “녹색 모자를 쓰는 것은 주사위의 결과에 영향을 미치지 않는다”가 될 것이다. 그리고 녹색 모자를 쓴 채 주사위를 던져서 20을 얻었다. 이때 p값은 어떻게 될까? 0.05이다.
\[ P(\text{E}|H_0) = \dfrac{1}{20} = 0.05 \]
(약간 에누리를 더해서) 10% 유의 수준에서 해당 영가설을 넉넉하게 기각할 수 있다! 좀 더 사악한 경우를 상상해볼까? 녹색 모자를 쓰고 주사위를 1000번 쯤 던졌다고 하자. 주사위가 정상이라면 50번 정도는 20이 나왔을 것이다. 해당 장면들만을 편집해서 마치 20번을 던진 것처럼 보이게 만들었다고 하자. 보라, 놀라운 녹색 모자의 효과를!
“녹색 모자를 쓰고 주사위를 던질 때 20이 더 잘 나온다!” 당연히 이상하고 잘못된 진술이다. 수많은 D&D 플레이어들은 이 말이 틀리다는 것을 경험적으로 너무나(!) 잘 알고 있다.
베이즈 정리
사실 우리가 알고 싶은 것이 p값이 아닐지 모른다. 우리는 이 값과는 다른 조건부 확률, 즉 \(P(H_0 | \text{E})\)을 알고 싶은 것이다! 영가설을 기각할 때 찾아오는 쾌감을 기억하는가? 이 쾌감이 근거를 지니려면 \(P(\cdot)\)의 값이 충분히 작아야 한다!
이 문제를 다루는 데에는 베이즈 정리를 활용할 수 있다.
\[ P(H_0|\text{E}) = \dfrac{P(\text{E}|H_0)P(H_0)}{P(\text{E}|H_0)P(H_0) + P(\text{E}|\neg H_0)P(\neg H_0)} \]
우리가 알고 싶은 답, 즉 E를 관찰할 때 \(H_0\)가 맞을 확률에서 p값(\(P(\text{E}|H_0\))은 한 부분으로 들어갈 뿐이다. 앞서 살펴본 D&D의 사례를 응용해보자. 녹색 모자가 주사위에 어떤 물리적인 조작을 가할 수 있는 것이 아닌 이상 \(P(H_0)=0.99\)이라고 기대할 수 있다고 하자. 따라서 \(P(\neg H_0) = 1 - P(H_0) = 0.01\)이다. 앞서 보았듯이 p값은 0.05이다. 만일 녹색 모자가 어떤 이유에서건 영향을 줄 수 있다면 \(P(\text{E}|\neg H_0)=1\)라고 강하게 기대할 수 있다.
\[ P(H_0|\text{E}) = \dfrac{0.05 * 0.999}{0.05 * 0.999 + 1 * 0.001} \approx 0.98 \]
20이라는 주사위의 관찰이 영가설의 신뢰성을 약간 훼손시키긴 했지만 그 정도가 심하지는 않다. 이게 대체로 상식적인 결과일 것이다.
이거 보면 뭔가 떠오르는 게 있는 분들이 있을지도 모르겠다. 유병률이 낮은 질병의 경우 테스트의 정확도(겅정력)이 높더라도 해당 테스트의 양성이 바로 아주 높은 확률의 질병 발생을 의미하지는 않는다. 이게 베이즈 정리의 신비인 것이다.
p값은 중요하다! 하지만 p값을 강한 의미로 해석하려면, 즉 영가설이 어느 정도나 옳은지의 맥락에서 해석하려면 베이즈 정리의 눈, 즉 사전 지식 혹은 믿음의 맥락에 입각해 한번 더 생각해봐야 할 것이다.
p값은 검정의 ’성과 지표’가 아니다!
p값이 낮으면 낮을수록 좋은 것일까? 이 질문은 미묘하다. p값은 오탐률(false positive)을 통제한다. 여기서 오탐이란 “영가설이 맞는데도 이를 잘못 기각”하는 경우를 의미한다. 오탐률이 낮으면 당연히 좋다. 즉 오탐이 아니라 탐지 못한 것이 맞는 경우, 즉 영가설이 참이면 p값은 아무런 의미가 없다. 다시 베이즈 정리로 돌아가보자.
\[ P(H_0|\text{E}) = \dfrac{P(\text{E}|H_0)P(H_0)}{P(\text{E}|H_0)P(H_0) + P(\text{E}|\neg H_0)P(\neg H_0)} \]
p값은 \(P(\text{E}|H_0)\)이다. 통계적인 검정력(statistical power)이란 \(P(\text{E}|\neg H_0)\)를 의미한다. p값과 같은 맥락에서 해석해보자. 해당 증거를 보고 영가설을 올바르게 기각할 확률이 된다. 즉 이는 true positive의 확률을 의미한다. 그리고 prevalence, 즉 유병률은 \(P(\neg H_0)\)이다. 이는 검정하려는 가설에 관한 일종의 사전 정보 혹은 믿음을 나타낸다.
1종 오류와 2종 오류
위의 내용은 1종 오류, 2종 오류 그리고 이진 분류와 관련되어 있다.
| \(H_0\) is true | \(H_0\) is false | |
|---|---|---|
| reject \(H_0\) | false positive(\(\alpha\)) | true positive(\(1-\beta\)) |
| aceept \(H_0\) | true negative(\(1-\alpha\)) | false negative(\(\beta\)) |
| Negative | Positive | |
|---|---|---|
| predicted Positve | false positive(\(\alpha\)) | true positive(\(1-\beta\)) |
| predicted Negative | true negative(\(1-\alpha\)) | false negative(\(\beta\)) |
몇 가지 용어를 정리해보자.
- false positive의 허용 확률 \(\alpha\)가 1종 오류(type I error)이다. 유의수준(significance level)이라고도 한다.
- false negative의 허용 확률 \(\beta\)가 2종 오류(type II error)이다. \((1-\beta)\)를 통계적 검정력(statistical power)이라고 한다.
- 세계의 상태가 결정되어 있다고 하자. 결정된 세계의 상태는 위의 표에서 두 열 중 하나다. 따라서 해당 열에 대한 허용 확률의 합은 1이 된다. 즉, 오탐(false positive) + 정미탐(true negative)의 확률, 그리고 정탐(true positive) + 미탐(false negative)의 확률은 각각 1이어야 한다.
- 행의 합은 그렇지 않다. 왜그럴까?
- Negative의 크기를 \(N\), Positive의 크기를 \(P\)라고 하자. 이때 유병률은 \(\frac{P}{P+N}\)이다. 이 값은 \(P(\neg H_0)\)와 같다.
\(\alpha\)와 \(\beta\)의 tradeoff
우리가 알고 싶은 값을 \(\alpha\), \(\beta\)를 넣어서 다시 써보자.
\[ P(H_0|\text{E}) = \dfrac{\alpha P(H_0)}{\alpha P(H_0) + (1-\beta)P(\neg H_0)} \]
증거 E를 관찰했을 때 영가설을 기각할 확률을 높이려면 위의 확률을 낮춰야 한다. \(\alpha\)와 \(\beta\)가 모두 낮을수록 해당 확률은 낮아진다. 그렇다면 이 둘을 모두 낮추면 좋지 않을까? 불행하게도 이는 불가능하다.
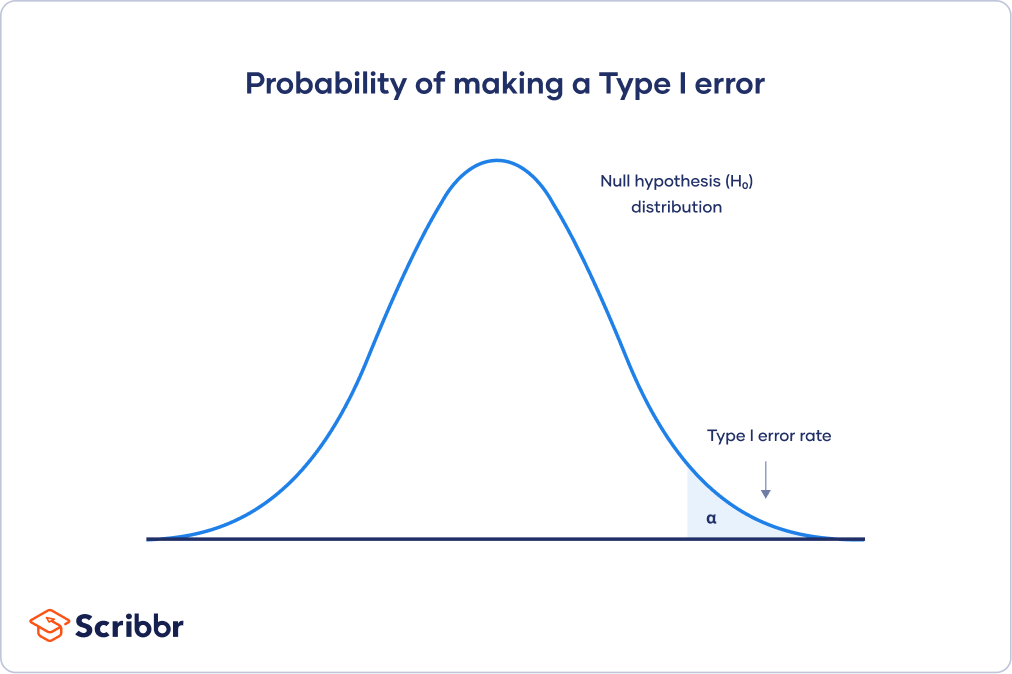
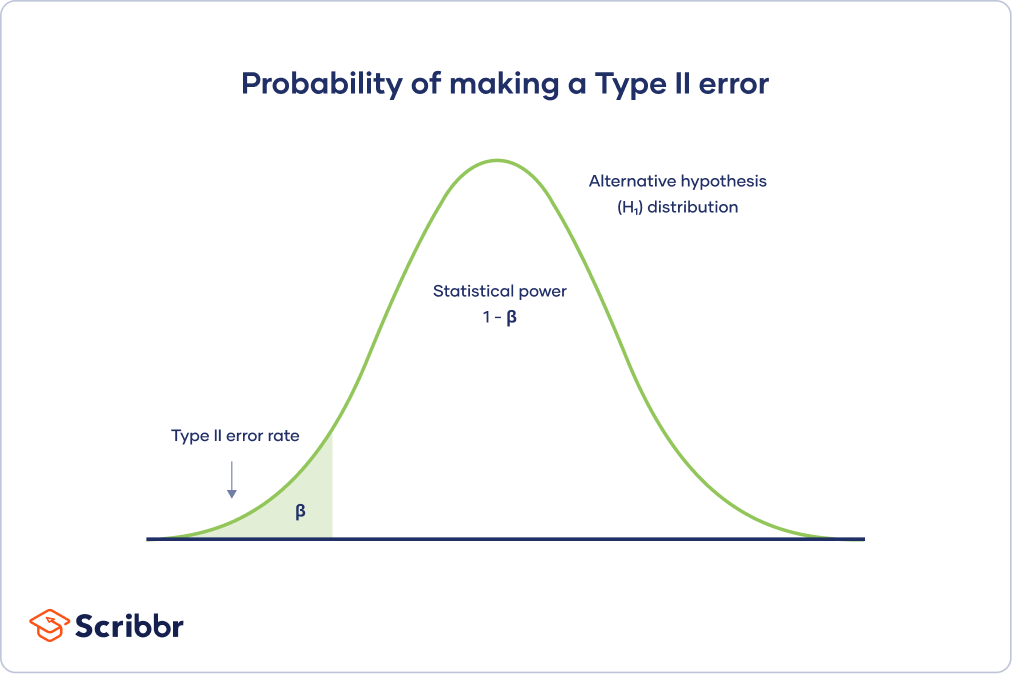
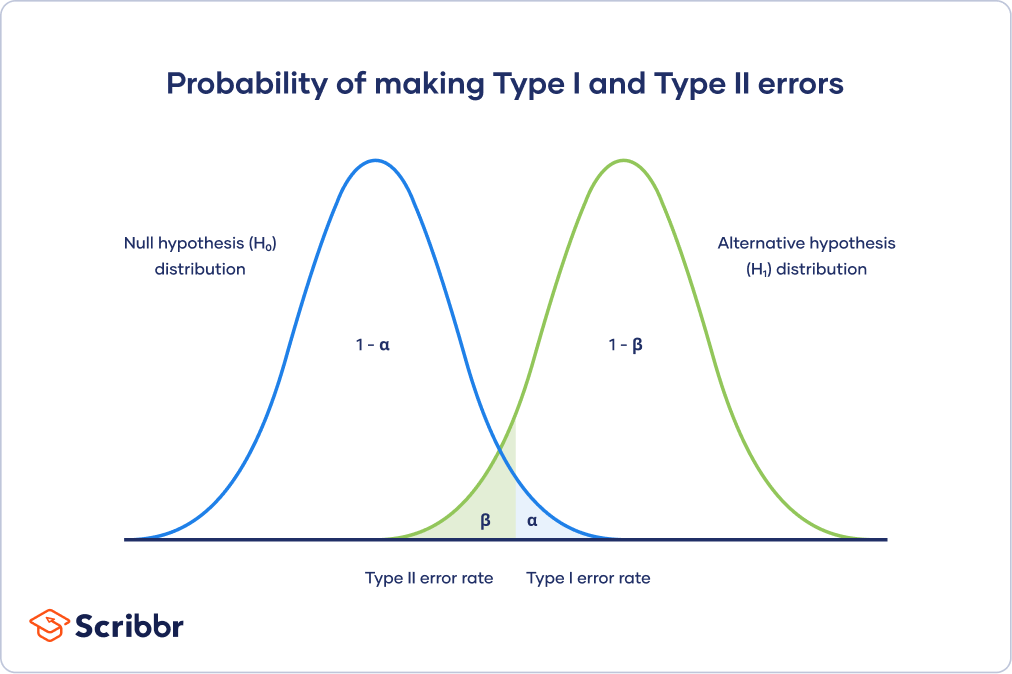
위 그림을 보자. 영가설을 잡았고 이론적인 대립가설은 그림과 같다. 만일 영가설과 대립가설이 충분히 떨어져 있어서 겹치는 부분이 없다면 행복할 것이다. 두 에러 모두 0으로 만드는 것이 가능하다. 하지만 이런 경우는 대체로 흥미롭지 않은 경우다. 통계적인 작업이 필요하지 않은 자명한 경우가 거의 대분일 것이다. 만일 사람들이 흥미로워하는데도 이런 통계학적인 상태에 있는 주제가 있다면 어서 논문을 쓰시기 바란다!
위 그림에서 보듯이 “any mean”을 기준으로 1종 오류와 2종 오류를 구별할 수 있는데, 두 분포가 겹치는 부분이 있는 이상 둘의 트레이드오프는 어쩔 수 없이 발생한다.
출판 편향과 p값
유병률이 낮은 경우 대부분의 관찰은 true negative에 속하게 된다. 이 경우는 흥미를 끌지 못하게 된다. 세간에서 “당연한 걸 뭘 보냐”라는 경우다.” 유병률이 낮을 때 유병(positive)을 관찰한다면 이건 주목을 끌게 된다. 이렇게 주목을 끌게 되는 그리고 주목을 끌고자 하는 저자의 의도가 출판 편향(publication bias)을 낳는다.
출판된 positive 중에서 true positive의 비율이 얼마나 될까? 이를 결정하는 것이 \(\alpha\), 즉 유의 수준과 통계적 검정력이 된다. 대략 \(\alpha=0.1\) 그리고 통계적 검정력(\(1-\beta\))를 0.6 정도를 가정하자. 이 정도도 관대한 것이다. 그리고 출판 편향이 문제가 되는 상황을 보기 위해서 유병률은 0.1 정도라고 가정하자. \(N=900, P=100\)이라고 가정하고 각각의 셀의 숫자를 채워보자.
| \(H_0\) is true (\(N=900\)) | \(H_0\) is false (\(P=100\)) | |
|---|---|---|
| reject \(H_0\) | false positive(0.1), 90 | true positive(0.6), 60 |
| accept \(H_0\) | true negative(0.9), 810 | false negative(0.4), 40 |
Positive라고 보고한 결과, 즉 \(H_0\)을 reject한 연구 중에서 오직 40%(\(\frac{60}{90+60}\))만 타당한 결과다. 나머지 60%는 false positive에 속한다!
p값은 낮을수록 좋은가?
만일 \(P(\text{E}|\neg H_0)\) 혹은 \((1-\beta)\)의 값이 고정되어 있다면, p값, 즉 \(\alpha\) 혹은 \(P(\text{E}|H_0)\)값이 낮을수록 \(P(H_0|\text{E})\) 역시 작아질 것이다. 하지만 위에서 보듯이 영가설과 대립가설의 분포가 겹쳐 있는 상황에서 p값이 작다는 것 즉, 1종 오류를 아주 작게 줄인다는 것은 대개의 경우 2종 오류를 늘이게 된다. 즉, \((1-\beta)\)는 작아지고 우리가 마음 속으로 바라고 있는 값, E라는 증거가 발견되었는데도 영가설 \(H_0\)가 맞을 확률은 높아진다. 이 때 \(\alpha\)와 \(\beta\) 중에서 어떤 것이 \(P(H_0|\text{E})\) 변화에 더 큰 영향을 줄것인지는 따져봐야 알 수 있다.
그래서, 뭐 어쩌라고?
통계학은 그 단어와 학문이 품은 ‘모호함’ 만큼 조심스럽게 해석하고 접근해야 한다. 세상의 모든 일이 그렇지만 언제나 ’맥락’이 중요하다. 오늘의 교훈이다. p값 역시 그러한 맥락을 잊지 말자.