전체와 부분
TL; DR
- 회귀 분석에서 ’통제’한다는 것의 의미를 전체와 부분이라는 시야에서 다시 음미해 보자.
- 교란 요인(confounder)와 충돌 요인(collider)을 심슨의 역설과 벅슨의 역설로 연결해 생각해 보자.
회귀 분석에서 ’통제’한다는 것
회귀 분석에서 독립 변수 혹은 설명 변수와 통제 변수의 차이는 개념적인 것이다. 즉, 내가 갖고 있는 분석의 초점 혹은 모델의 취지에 따라 결정되는 것이지 어떤 기계적인 방법이나 기준은 없다. 일단 ’통제’에 초점을 맞춰서 생각해 보자. 아래와 같은 간략한 회귀 모형을 생각해 보자.
\[ y_i = \alpha + \beta x_i + \gamma D_i + \epsilon_i \]
\(x_i\)는 설명 변수, \(D_i\)는 통제 변수라고 하자. 이해를 돕기 위해서 \(D_i\)는 0, 1의 값을 갖는 더미 변수다. \(D_i\)를 통제한다는 것의 의미는 무엇일까? \(x_i\)가 \(y_i\)에 미치는 영향을 그냥 전체로 보지 않고 두 집단 별로 나눠서 보겠다는 것이다. 이때 최소자승법을 통해 계산되는 \(\beta\)는 \(D_i\)로 구별되는 집단 각각의 효과를 구한 뒤 이를 적절하게 가중 평균한 값이 된다. ’통제’란 설명 변수의 효과를 보다 정교하게 보기 위해서 관찰을 통제 변수로 구성된 집단으로 나누는 것이라고 생각하면 쉽다. 카테고리로 구별된 집단뿐 아니라 연속 함수에 관해서도 비슷하게 이해하면 된다.
Angrist와 Pischke가 이런 맥락에서 회귀 분석이 자동화된 짝짓기(matching) 기계라고 설명한 바 있다.
Confounder and Simpson’s Paradox
먼저 심슨의 역설을 먼저 살펴보자. 아래는 웃자고 만든 그림인데 웃고 넘기기에는 아까운 중요한 통찰이 들어 있다.
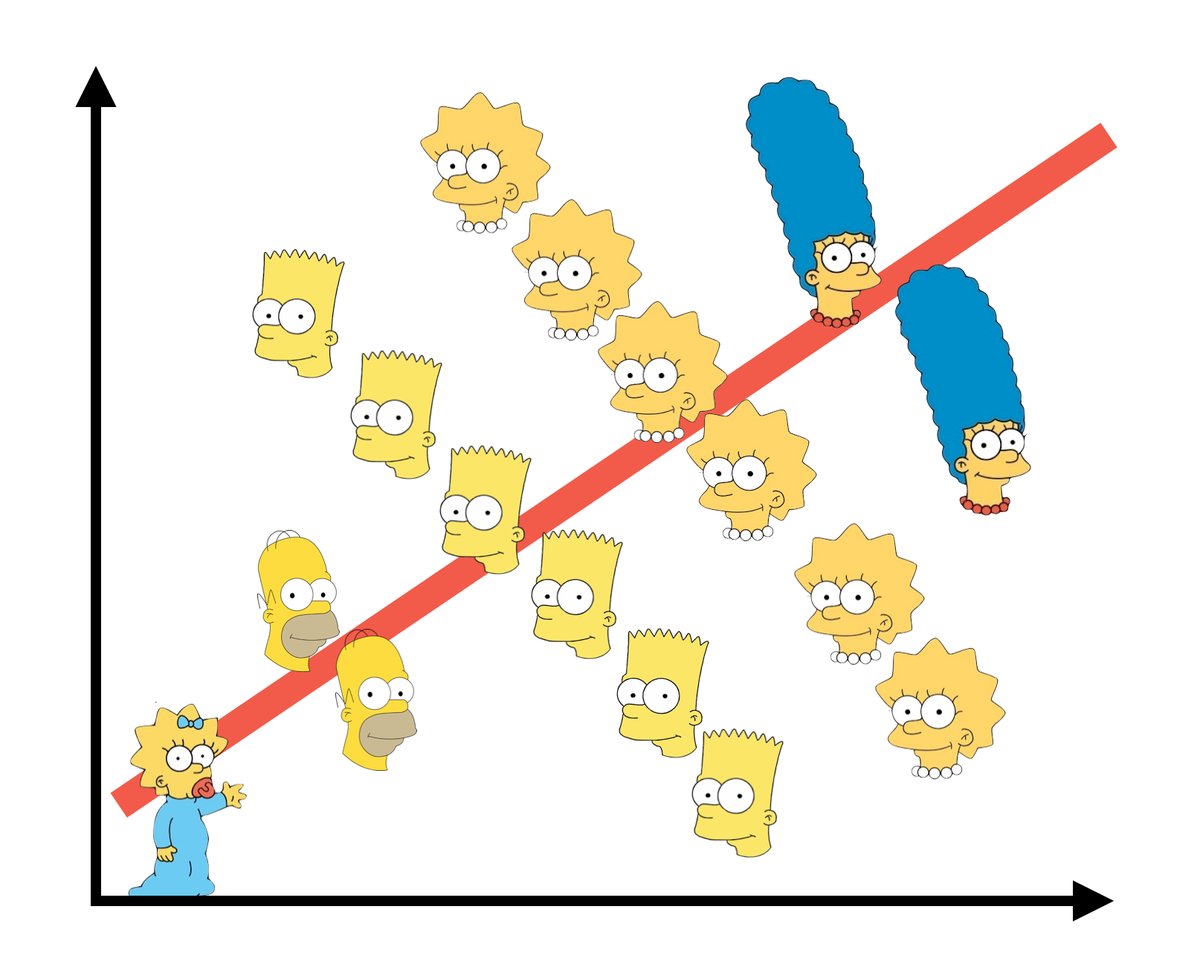
위 그림에서 심슨가족 전체를 보면 \(x\) 축 변인의 증가에 따라서 \(y\) 축 변인이 증가하는 형태를 취한다. 반면, 가족 구성원 하나하나에 대해서는 반대의 관계를 취하고 있다. 심슨의 역설은 전체의 경향과 부분의 경향이 어긋나는 현상을 나타낸다. 조금 더 진지한 사례는 아래의 그림과 같다.

여기서 중요한 것은 역설 자체가 아니다. 역설의 함정에 빠지지 않고 어디에 포커스를 둘 것인지가 문제다. 만일 인구 구성의 각 그룹 별 경향을 평균적으로 살펴보는 것이 관심 사항이라면 위 그림에서 그룹 각각의 기울기를 평균한 값이 우리가 찾는 경향이다. 반대로 개별 그룹은 중요하지 않고 인구 전체가 관심사라면 개별 인구를 동일하게 보고 기울기를 찾는 게 맞다.
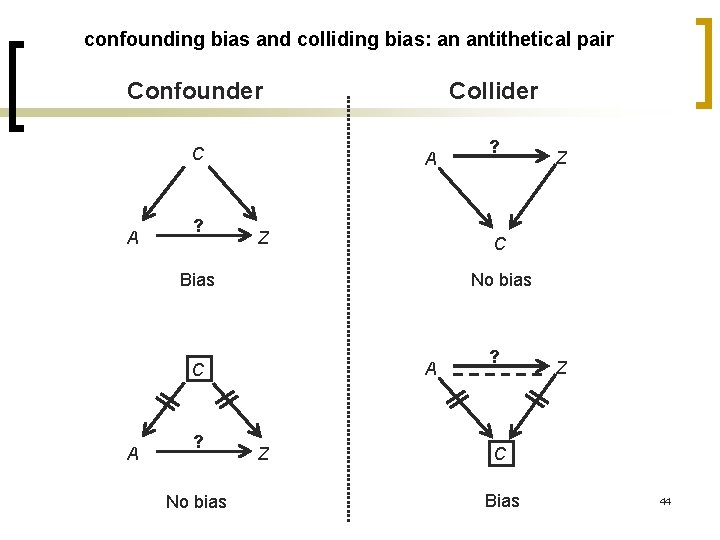
심슨의 역설은 DAG(Directed Acyclic Graph)를 통한 인과 추론에서 교란 요인(confounder)에 해당한다. A –> Z가 현재 우리가 관찰하는 사실이다. 예를 들어, 교육 수준이 높을수록 졸업 후 취업 시 임금이 높다. 하지만 이는 교육 수준과 임금 모두에게 영향을 미치는 제3의 요인을 고려하지 않는 것일지도 모른다. 교육 수준과 임금 모두에게 영향을 주는 미처 파악하지 못한 변인, 예를 들어 능력치(C)가 있다고 하자. 이 능력치는 교육 수준과 임금 모두에게 영향을 준다.
이 능력치를 그룹화해서 비교하는 게 가능하다고 가정하자. 이는 위의 심슨 가족 그림에서 가족별로 각 그룹을 나누는 것에 해당한다. 이렇게 능력치를 고려하면 교육은 오히려 졸업 후 임금을 낮출 수도 있다. C(능력치)라는 변수를 명백하게 고려하면 A(교육 수준)가 Z(임금)에 미치는 영향의 크기가 변할 수 있다. 예컨대, C를 고려하지 않았을 때 존재하던 A–>Z의 효과가 사라지거나 기대했던 것과 반대의 효과를 지닐 수도 있다.
그래도 심슨의 역설이 잘 이해가 되지 않는다면…
벡터를 통해 그래프로 설명하는 사례가 직관적으로 잘 와닿고 이해하기도 좋다.

Collider and Berkson’s Paradox

이번에는 벅슨의 역설을 살펴볼 차례다. 보통 수능 점수와 대학 성적은 별 관련이 없고 심지어 역의 상관성이 있다는 이야기를 접할 때가 있다. 이것은 맞는 주장인가? 이런 종류의 주장은 대체로 전체를 가정한다. ‘수능 점수와 대학 성적이 별로 상관이 없으니, 수능은 인간의 능력을 판단하는 지표로 별로 유용하지 않아.’ 이야기가 이렇게 흐르기 마련이다.
위의 그림에서 보듯이 이러한 경향은 보편적인 주장이 아니라 특정한 집단 내에서만 타당한 주장이다. 위 그림에서는 내가 관찰하는 집단에 대해서 일종의 자기 선택이 일어난 경우에 해당한다. 내가 속한 밴드의 집단보다 수능 점수와 대학 성적이 모두 낮은 집단은 내가 속한 관찰 집단과는 다른 집단에 속한다. 반면 내가 속한 밴드보다 수능 점수도 높고 대학 성적도 우월한 집단도 마찬가지다.
벅슨의 역설은 심슨의 역설과 동일하지만 반대의 측면을 지적한다. 전체 대해서 존재하는 경향성이 그룹으로 쪼개서 보면 반대가 되거나 사라지는 경우를 의미한다.
벅슨의 역설에 해당하는 인과 추론의 DAG 사례가 충돌 요인(collider)이다. 변수를 고려하지 않았다면 전체에 관해서 온전한 주장이 성립했을 것이지만, 해당 변수를 고려해 그룹을 나누게 되면 오히려 잘못된 관계를 추정하게 된다.
벅슨의 역설은 통제하지 않아야 할 변수를 통제할 때 발생하기도 하지만 많은 경우 표본 자체를 살피지 않은 데에서 생기기도 한다. 예를 들어 아래 그림을 보자.
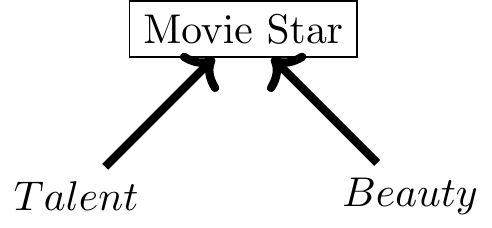
보통 배우가 되려면 연기 재능과 외모 둘 중 하나는 갖추어야 한다고들 한다. 이 말 자체는 맞지만 이를 확대 해석해서 외모와 연기 재능이 역의 상관성이 있다고 주장하는 경우가 있다. 이는 모집단 전체(모든 사람)에 대해서 타당한 말일까? 배우라는 집단으로 제한해보면 외모와 재능이 모두 미달되는 사람들은 배우가 아닌 다른 직업을 찾았을 가능성이 높다. 외모와 재능을 사분면으로 나눌 때 3 사분면에 위치한 사람들이 사라진 배우라는 집단에 대해서는 음의 상관성이 관찰되는 것처럼 보인다.
중요한 것은 질문과 문제 설정
이렇게 보면 심슨의 역설이든 벅슨의 역설이든 어떤 절대적인 규칙을 알려주는 것이 아니다. 관심을 두는 실증의 효과가 어떻게 작용하는 효과인가라는 질문이 먼저이다. 연구가 전체에 관한 특성을 묻는 질문이라면 충돌 요인(collider)이 변수에 없는지 살펴봐야 한다. 반면 집단을 나누는 것이 효과를 살펴보는 데 중요하다면 교란 요인(confounder)에 주의해야 한다. 충돌 요인이든 교란 요인이든 둘 다 실증 연구를 오도할 수 있지만 방해하는 수준이 다르다.
이제 회귀 분석에서 통제한다는 것의 의미를 다시 정리해 보자. 회귀 분석의 모델링의 관점에서 보면 통제 변수와 설명 변수 간에 차이가 없다. 연구자의 의도에 비춰 볼 때 통제 변수는 설명 변수에 의도하지 않은 영향이 포함되는 것을 막아 준다. 앞서 말했듯이 회귀 분석은 통제 변수에 따라서 관찰을 여러 그룹으로 나누고 이에 따라서 설명 변수의 효과를 자동으로 계산하는 기계이다. 무엇인가를 통제하지 못했다는 것은 이 설명 변수에 그 효과까지 함께 포함되는 것을 의미한다. 이런 상황에서 발생할 수 있는 사례 중 하나가 심슨의 역설이다. 반면, 넣지 말아야 할 변수를 넣는다는 것은 설명 변수의 효과를 과장하는 결과를 낳는다. 그리고 특정한 인구 집단 혹은 경우에 발생한 일을 일반화해 주장하게 되는 것은 벅슨의 역설이다.
이렇게 보면 심슨의 역설과 벅슨의 역설은 회귀 분석에서 모델링의 중요성 혹은 적절한 중도를 지키는 것이 얼마나 어려운지를 잘 보여준다. 회귀 분석의 길은 앵그리스트와 피스케 선생이 말했듯이 진정 “도”의 길이었던 것이다!