Understanding Log-Linear Regression Model
당연히 알고 있다고 생각하지만 모르는 게 생각보다 많다. 회귀 분석에서 로그-리니어 모델, 즉 종속 변수에 로그를 취하고 독립 변수가 선형인 모델에서 계수를 어떻게 이해해야 할까?
왜 로그로 변환할까?
우선 이것부터 따져보자. 교과서나 자료를 찾아보면 \(y_i\)를 로그 변환하는 이유가 \(y_i\)의 분포를 정규분포에 가깝게 만들어주기 때문이라는 내용이 있다. 소표본을 다루는 경우라면 오차 항의 정규 분포를 가정하기 때문에 타당한 이야기일 수도 있다. 대표본이라면 중심 극한 정리(Central Limit Theorem)에 의지하는 것으로 충분하다.
우선 아래 그림에서 보듯이 로그로 변환했을 때 회귀 분석이 보다 타당해지는 경우가 있다. 로그는 곱셈을 덧셈으로 폴어주는 역할을 한다. \(y_i = e^{\alpha \beta x_i}\)의 경우 함수 형태가 \(e^\alpha\)와 \(e^{\beta x_i}\)의 곱으로 구성되어 있고, 이 녀석을 회귀 분석으로 추정하는 것은 적합하지 않다. 이때 \(\log y_i\)를 취하면 회귀 분석으로 다루기 좋은 녀석으로 바뀐다.
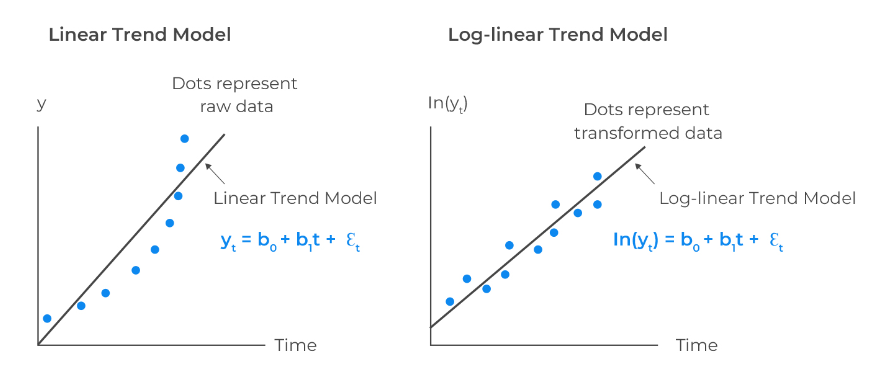
곱으로 표현되는 식이 어떤 경우가 해당할까? 어떤 기준점의 몇 배로 늘고 주는 것이 자연스러운 맥락을 떠올려보자. 여기서 몇 배가 된다는 것은 다시 말하면 퍼센트 변화를 뜻한다. 즉, 로그 변환은 수치의 절대적인 변화량보다는 퍼센트 변화가 의미를 지닐 때 유용하게 사용할 수 있다.
비슷한 맥락이지만 데이터의 분산이 클 때도 로그 변환이 유효하다. 부(wealth)의 분포는 극단적인 경우가 많다. 매우 적은 부를 소유한 사람부터 매우 많은 부를 소유한 사람까지 분산이 매우 크다. 이런 경우 로그 변환을 하면 분산이 크게 줄어든다.
근삿값으로 본 계수의 의미
편의상 독립 변수와 종속 변수 모두 스칼라 값인 아래와 같은 로그-선형 모형을 살펴보자.
\[ \ln y_i = \alpha + \beta x_i + \varepsilon_i \]
\(\Delta \ln y_i\)의 의미를 풀면 다음과 같다.
\[ \begin{aligned} \Delta \ln y_i & = \ln y_1 - \ln y_0 \\ & = \ln(\frac{y_1}{y_0}) \\ & = \ln(\frac{y_0 + \Delta y}{y_0}) \\ & = \ln(1+\frac{\Delta y}{y_0}) \end{aligned} \]
\(\ln(1+\frac{\Delta y}{y_0})\)를 보자. \(z=0\) 근처에서 \(\ln (1+z) \approx z\)가 성립한다. 즉, 만일 \(\frac{\Delta y}{y_0} \approx 0\)라면,
\[ \Delta \ln y_i = \ln(1+\frac{\Delta y}{y_0}) \approx \dfrac{\Delta y}{y_0} = \% \Delta y = \beta \Delta x \]
이 경우 \(\beta\)가 \(x_i\) 변화에 따른 \(y_i\)의 변화율이라는 수학적인 해석을 그대로 가져올 수 있다. \(\frac{\Delta y}{y_0} \approx 0\)를 만족하려면 \(y_i\)의 변화율이 크지 않아야 한다. 로그-선형 모형의 회귀식을 추정해 \(\beta\)를 보고할 때 “\(x_i\)가 1단위 변화할 때”라는 표현을 쓴다. 이는 \(\Delta x = 1\)로 둔다는 뜻이다.
\[ \Delta \ln y_i \approx \dfrac{\Delta y}{y_0} = \% \Delta y = \beta \]
결국 \(\beta\)의 값이 0과 크게 다르지 않다면 이 값은 \(x_i\)가 1단위 변화할 때 \(y_i\)의 변화율에 미치는 영향”으로 해석할 수 있다.
변화율을 정확하게 계산해 보자
근삿값을 쓰지 말고 % 변화율을 정확하게 계산해 보자. 물론 이 값이 필요한 경우에 해당한다.
\[ \begin{aligned} \% \Delta y_i & \equiv \dfrac{y_1 - y_0}{y_0} \\ & = \dfrac{y_1}{y_0} - 1 \\ & = \exp(\ln (\dfrac{y_1}{y_0})) - 1 \\ & = \exp(x_1 \beta - x_0 \beta + \varepsilon_1 - \varepsilon_0) - 1 \\ & = \exp(\Delta x \beta + \Delta \varepsilon) - 1 \end{aligned} \]
\(z=0\) 근방에서 테일러급수를 1차까지 근사하면 저 값을 얻을 수 있다. \(z=0\) 인근에서 근사하는 이유는 \(z=0\) 근처에서 \(\frac{(z-0)^k}{k!}\) for \(k=2,3, \dotsc\)과 같은 고차 항의 크기가 점점 줄어들기 때문이다.
\(\Delta \varepsilon =0\)를 가정하고 \(\Delta x =1\)로 두면, 위 식으로 \(y_i\)의 % 변화율을 계산할 수 있다.
계수의 해석
지수 함수 \(e^x\)의 그래프를 생각해 보자. \(x\)가 커짐에 따라서 도함수의 기울기가 커진다는 점을 알 수 있다. 위의 전개에서 보듯이 \(\frac{\Delta y}{y_0} \approx 0\)일 때 \(\beta\)는 실제의 도함수 기울기에 값에 근접한다. \(\frac{\Delta y}{y_0} \approx 0\)의 가정이란 \(y\)의 증가율이 크지 않다는 의미이다. 예를 들어보자. 만일 \(\beta = 0.3\)이라고 하자. 실제 \(\%\Delta y\)를 구해보면,
\[ \%\Delta y = \exp(\beta) - 1 = 0.35 \]
약 5% 정도 과소평가되었음을 알 수 있다. 이 크기의 의미나 중요성은 분석자가 선택할 문제다. 다만 \(\beta\)가 너무 크게 나왔다면, 실재 값과의 오차가 생길 수 있다. 로그-선형 모델의 경우 원래 크기보다 퍼센트 변화를 과소 측정한다. 원래 지수적으로 늘어나는 것을 로그를 취해 선형으로 끌어내린 결과이다.