Understanding Logit Regression
TL; DR
- 로짓 회귀는 우리가 알던 그 ’회귀’와 다르다!
- 로짓 회귀는 아래와 같은 데이터 모형에 기반을 둔 추정법이다.
\[ \ln \dfrac{p(\boldsymbol{x_i})}{1-p(\boldsymbol{x_i})} =\boldsymbol{x_i}\boldsymbol{\beta} \]
- 회귀식의 계수 \(\boldsymbol{\beta}\)를 해석할 때 주의하자. 이를 통상적인 회귀 분석의 계수(한계 효과)처럼 해석하려면 별도의 계산이 필요하다.
로짓 회귀, 제대로 알고 있나?
기계 학습을 배우게 되면, 로짓 회귀는 첫 챕터에서 그냥 쓱 지나치기 쉽다. 이어 등장하는 랜덤 포레스트, SVM, 뉴럴넷 등이 더 진보된 방법으로 보이기 때문이다. 로짓 회귀는 단순하면서도 강력한 방법이다. 나는 분류(classification)의 문제에 접근할 때 로짓 회귀를 먼저 해본다. 로짓 회귀에서 ’견적’이 나오면 그 질문 혹은 문제는 더 흥미로운 형태로 진화할 가능성이 높다. 반면 로짓 회귀에서 싹수가 없으면 더 복잡한 고급 방법도 소용이 없는 경우가 많다. 요컨대 로짓 회귀는 시간 낭비를 막는 일종의 ’맛보기’로서도 유용하다.
로짓 함수는 어떻게 등장하나?
로짓 회귀는 말 그대로 로지스틱 함수(logistic function)를 활용하는 회귀 분석이라는 뜻이다. 로지스틱 함수는 어디서 어떻게 등장할까? 로짓 회귀의 데이터 형태부터 살펴보자. 종속 변수, 반응(response), regressand 등 다양한 형태로 불리는 식의 좌변은 0 또는 1로만 되어 있다. 어떤 상태라면 1, 그렇지 않으면 0이다. 이때 0 또는 1은 값 자체로 의미를 지니지 않는다. 이는 범주형 변수로서 True or False와 같은 이항 변수로 이해하면 좋겠다. 식의 우변에는 통상적인 독립 변수, 예측 변수(predictor)가 등장한다.
생각난 김에 짬을 내 회귀식에서 좌변과 우변을 지칭하는 용어를 정리해보자. 취향에 맞춰서 쓰되 일관성만 갖추면 되겠다.
| 좌변 | 우변 |
|---|---|
| \(y\) | \(x\), \(\boldsymbol X\) |
| dependent variable | independent variables |
| response variable | predictor variable |
| regressand | regressor |
| criterion | covariate |
| predicted variable | controlled variable |
| measured variable | manipulated variable |
| explained variable | explanatory variable |
| experimental variable | exposure variable |
| responding variable | covariate |
| outcome variable | covariate |
| output variable | input variable |
| endogenous variable | exogenous variable |
| target | feature |
| label | feature |
어떤 경우 OLS는 곤란한가?
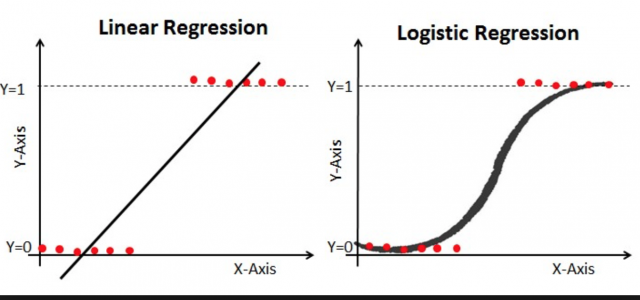
독립 변수가 하나인 모형을 가정하고 위의 그림을 보자. 종속 변수가 0, 1인 상태로 그대로 회귀 분석을 하면 그림의 왼쪽 같이 된다. 회귀식의 기울기를 구할 수 있으니 된 것 아니냐? 아니다. 앞서 0과 1은 값 그 자체로 의미를 지니지 않는다고 말했다. 그런데 이를 그대로 값으로 바꿔서 회귀 분석을 해도 좋은 것일까? 그러기에는 어딘가 찜찜하다.
게다가 \(x\) 값에 따라서 회귀식의 예측치가 \([0,1]\)을 벗어날 수 있다. 임의로 계단 함수를 다시 얹어서 OLS(통상적인 최소자승법이라는 의미에서 Ordinary Least Squares라고 흔히 부른다)를 구제할 수도 있겠다. 즉,
\[ s(\beta x) = \begin{cases} 1 & \text{if $\beta x \geq 1$} \\ 0 & \text{if $\beta x < 0$} \end{cases} \]
회귀식의 예측을 확률에 맞게 임의로 꺾어주는 것이다. 이러한 과정을 조금 더 ‘부드럽게’ 혹은 보다 ‘그럴 듯하게’ 할 수 없을까?
범주형에서 확률로
앞서 0, 1은 값 자체로는 아무 의미를 지니지 않는다고 말했다. 통상적인 회귀 분석의 종속 변수는 실수 형태다. 그렇다면 0, 1을 실수로 바꾸면 어떨까. 범주형 변수가 결국 상태를 나타내는 것이라면 1이라는 상태를 지닐 ’확률’을 추정하는 문제로 바꿔 생각해볼 수 있겠다. 즉,
\[ p(y_i = 1 | \boldsymbol{x_i}) = p(\boldsymbol{x_i}) \]
그런데 앞서 보았듯이 확률 값을 선형 회귀로 추정하는 데에는 어려움이 있다. 통상적인 회귀 모형의 특성을 유지하면서도 확률 값을 [0,1] 사이에 ‘잘’ 떨구는 일이 무척 귀찮다. 식을 아래와 같이 변형해보도록 하자.
\[ \dfrac{p(\boldsymbol{x_i})}{1-p(\boldsymbol{x_i})} \]
종속 변수를 이렇게 바꾸면 가능한 값의 범위가 \([0, \infty)\)로 확장된다. 여기에 자연 로그를 적용해보자.
\[ \ln \dfrac{p(\boldsymbol{x_i})}{1-p(\boldsymbol{x_i})} \]
이제 가능한 값의 범위가 \((-\infty, \infty)\)가 된다. 이제 보통의 선형 회귀를 적용해도 좋겠다.
즉,
\[ \ln \dfrac{p(\boldsymbol{x_i})}{1-p(\boldsymbol{x_i})} = \underset{1 \times k}{\phantom{\boldsymbol{\beta}}\boldsymbol{\boldsymbol{x_i}} \phantom{\boldsymbol{\beta}}}\underset{k \times 1}{\boldsymbol{\beta}}, ~k = 1, 2, \dotsc, n \]
\(n\) 개의 관찰에 있을 때 이를 매트릭스 형태로 적으면 다음과 같다.
\[ \ln \dfrac{p(\boldsymbol{X})}{1-p(\boldsymbol{X})} = \underset{n \times k}{\phantom{\boldsymbol{\beta}}\boldsymbol{X}\phantom{\boldsymbol{\beta}}}\underset{k \times 1}{\boldsymbol{\beta}} \]
애석하지만 이 식은 우리에게 주어진 자료로는 추정할 수 없다. 좌변의 종속 변수를 얻으려면 확률 함수를 알아야 하는데 이 녀석은 영원히 미지의 사실이다. 따라서 위의 식은 선형 회귀를 적용할 수 있는 방법을 고안한 것일 뿐 실제로 추정 가능한 식이 아니다. 그렇다면, \(\boldsymbol{\beta}\)는 어떻게 구해야 할까?
이 문제를 살펴 보기 전에 위의 모형에서 로지스틱 함수를 발견해보자. 위의 식에서 \(p(x_i)\)를 구해보자.
\[ \begin{aligned} \ln \dfrac{p(\boldsymbol{x_i})}{1-p(\boldsymbol{x_i})} & =\boldsymbol{x_i}\boldsymbol{\beta} \\ \dfrac{p(\boldsymbol{x_i})}{1-p(\boldsymbol{x_i})} & = e^{\boldsymbol{x_i}\boldsymbol{\beta}} \\ p(\boldsymbol{x_i}) & = \dfrac{e^{\boldsymbol{x_i}\boldsymbol{\beta}}}{1+e^{\boldsymbol{x_i}\boldsymbol{\beta}}} \\ p(\boldsymbol{x_i}) & = \dfrac{1}{e^{-\boldsymbol{x_i}\boldsymbol{\beta}} + 1} \end{aligned} \]
앞서 본 그림의 오른쪽과 같은 형태의 로지스틱 함수가 도출된다. 요컨대, 로지스틱 함수는 독립 변수를 해당 사건이 발생할 확률과 연결시키는 장치다. 이렇게 보면 로지스틱 회귀는 이른바 일반 선형 모형(Generalized Linear Model)의 한 사례다. 일반 선형 모형이란 종속 변수, 즉 식의 왼쪽이 어려가지 이유에서 실수 값이 아닌 제한된 값 혹은 범주 값을 지닐 때 이를 여러가지 방법을 통해 실수로 바꾸는 방식으로 추정을 하는 방법이다. 지금까지 살펴본 방법이 그 사례의 하나다.
Link function
말이 나온 김에 “링크 함수”를 한번 보고 가자. 위에서 보듯이, 사실 회귀 분석이란 실수의 범위를 지니는 좌변을 역시 변수의 선형결합을 통해 이루어진 우변으로 설명하려는 것이다. 그런데 만일 좌변의 영역이 실수 전체가 아니라면? 예를 들면 아래와 같다.
- 절단 자료 (truncated): 지속 시간의 경우 0보다 큰 실수가 된다.
- 범주형 자료: 이 경우는 수로 표현하려면 적절한 변형이 필요하다.
- 정수형 자료
이럴 때는 어떻게 해야 할까? 회귀 분석의 틀을 벗어나지 않으면서 가장 간단한 해결책은 좌변을 바꾸는 것이다. 좌변은 어떻게 바꿔야 할까? 우선 좌변에 올 것의 조건부 평균을 다음과 같이 두자. 로지스틱 회귀에서 이 조건부 평균이 해당 상태가 될 , 즉 1의 값을 지닐 확률과 같다.
\[ \mathrm E (y_i | \boldsymbol x_i) =\mu_i \]
그리고 우변의 경우 평범하게 다음과 같이 두자.
\[ \eta_i = \beta_0 + \beta_1 x_{i1} + \dotsb + \beta_p x_{ip} \]
이 둘은 바로 연결이 안된다. 이 둘을 연결시켜주는 어떤 함수가 있다면? 즉,
\[ g(\mu_i) = \eta_i = \boldsymbol x_i^T \beta \]
\(g(\cdot)\)이 링크 함수에 해당한다. 로짓 회귀의 경우에는 \(\ln \frac{p(x_i)}{1-p(x_i)}\)에 해당한다. 링크 함수의 역함수는 뭐라고 부를까? 로짓 회귀에서 아래의 값에 해당한다.
\[ p(\boldsymbol{x_i}) = \dfrac{1}{e^{-\boldsymbol{x_i}\boldsymbol{\beta}} + 1} \]
이는 평균 함수(mean function)이라고 부른다. 로짓 회귀의 경우는 이산 변수를 활용하기 때문에 확률 질량 함수가 곧 확률이 된다는 점을 기억해두자.
삼단계
위 과정이 세 가지 단계를 거쳤다는 점을 쉽게 알 수 있을 것이다.
\[ y_i \xrightarrow{\rm prob.~function} \mu_i \xrightarrow{\rm link~function} \eta_i = \boldsymbol x_i \beta \]
원래 관찰값 \(y_i\)는 확률 (질량/밀도) 함수를 통해 \(\mu_i\) 로 변형된다. 이는 다시 연결 함수를 통해서 선형 회귀가 가능한 형태로 변형된다.
\(y_i\)가 어떤 특성을 지니는지에 따라서 다양한 형태의 \(\mu_i\)가 가능하고, 여기에 적절한 연결 함수를 적용해야 한다. 이는 논의 범위를 벗어난다. 이 글을 참고하자.
계수는 어떻게 구하나?
\(\hat{\boldsymbol \beta}\)은 어떻게 구할 수 있을까? 현재까지 우리에게 주어진 조건을 보자.
- 종속 변수의 관찰값은 0 또는 1이다.
- 로짓 함수를 통해서 독립 변수를 해당 관찰의 확률과 연결시킬 수 있게 되었다.
어차피 종속 변수를 실수로 바꿀 수 없는 이상 우리가 아는 선형 회귀 분석을 쓸 수는 없다. 그래서 이름과 달리 우리가 아는 ‘회귀 분석’, 즉 OLS를 여기서 쓸 수는 없다. 미안하다. 앞에서 거짓말 했다.
\[ \ln \dfrac{p(\boldsymbol{x_i})}{1-p(\boldsymbol{x_i})} = \underset{1 \times k}{\phantom{\boldsymbol{\beta}}\boldsymbol{x_i}\phantom{\boldsymbol{\beta}}}\underset{k \times 1}{\boldsymbol{\beta}}, ~k = 1, 2, \dotsc, n \]
애초에 \(\boldsymbol \beta\)을 알고 있어야, 이 식으로부터 \(p(\cdot)\)을 구해낼 수 있다. 그런데 우리가 아는 회귀 분석이란 \(y\)와 \(\boldsymbol{\rm X}\)가 주어졌을 때 하는 것 아닌가? 회귀 분석의 좌변이 없기에 OLS로는 추정할 수 없다.
그래서 로짓 회귀는 이름과 달리 \(\boldsymbol{\beta}\)의 추정치 \(\hat{\boldsymbol\beta}\)를 구하는데 OLS의 방법을 쓰지 않는다. 로짓 회귀에서는 어떻게 \(\hat{\boldsymbol\beta}\)를 얻는 것일까?
확률 vs 우도
잠시 로짓 회귀의 추정을 살펴보기 전에 확률과 우도의 차이점에 관해서 알아보자. 분포와 그 분포의 파리미터를 알고 있을 때 해당 샘플이 관찰될 확률을 구할 수 있다. 연속 확률변수 \(x\)가 따르는 어떤 분포가 있다고 할 때, 해당 분포를 요약하는 파라미터(정규분포라면 평균과 분산이다) \(\theta\)에 대해서 \(P(x_1 < x <x_2 | \theta)\)를 구한다면, 이것이 확률이다.
우도(likelihood)는 무엇일까? 우도는 확률 분포의 수학적인 형태에서 관심의 대상을 바꾼 것이다. 위의 연속 확률변수의 예에서 \(P(\theta | x_1 < x < x_2)\)가 우도가 된다. 하나의 관찰 \(x_i\)에 대해서는 확률 밀도함수 \(f(\theta | x = x_i)\)를 우도로 정의할 수 있다. 연속 확률변수가 아니라 이산 확률변수라면, 확률 질량함수가 될 것이고 이 경우에는 확률과 같다.
요컨대 주어진 것(conditioning), 즉 무엇을 파라미터로 볼 것인지의 차이에 따라서 확률과 우도의 정의가 달라진다. 다시 정리해보자.
| 명칭 | 주어진 것 | 변수 | 형태 | |
|---|---|---|---|---|
| 확률 | 분포의 파라미터(\(\theta\)) | 관찰값 | \(P(x_1 < x < x_2 | \theta)\) | |
| 우도 | 관찰값 | 분포의 파라미터(\(\theta\)) | \(P(\theta|x_1 < x < x_2)\) |
연속확률 변수의 경우 하나의 관찰값에 대해서 확률은 이론적으로 정의되지 않지만, 우도는 정의된다. 이 경우 우도는 확률 밀도함수 \(f(\theta|x=x_i)\)를 따르게 된다.
최대 우도 추정(maximum likelihood estimation)
다시 문제로 돌아오자. 우리는 0, 1 즉 존재/비존재의 특징을 지니는 변수를 갖고 있다. 그리고 이 녀석은 이산 확률 분포를 따르기 때문에 우도 역시 그냥 확률이 되고, 이는 베르누이 분포를 따른다. 즉, 해당 확률이 발생할 확률 \(p\)일 때 발생하면 1, 아니면 0이 된다. 베르누이 분포의 확률 질량 함수를 간단하게 표현하는 방법은 없을까?
\[ L(y_i) = p(\boldsymbol{x_i}; \boldsymbol{\beta})^{y_i} (1-p(\boldsymbol{x_i}; \boldsymbol{\beta}))^{1-y_i} \]
위와 같은 식으로 간단히 해결된다. 위 식에서 \(y_i\)가 1이면 \(p(\cdot)\)가, 0이면 \(1-p(\cdot)\)가 할당된다. 이제 우리는 \(n\) 개의 관찰에 관해서 식의 좌변에는 0,1을 갖고 있다. 각각의 시행이 독립적이라고 가정하면 주어진 형태의 데이터를 관찰하게 될 우도는 이 확률을 곱한 것과 같다. 즉,
\[ L(y|{\boldsymbol X}) = \prod_{i = 1}^{n} L(y_i) = \prod p(\boldsymbol{x_i}; \boldsymbol{\beta})^{y_i} (1-p(\boldsymbol{x_i}; \boldsymbol{\beta}))^{1-y_i} = L(\boldsymbol{\beta}|y, {\boldsymbol X}) \]
\(\boldsymbol{\beta}\)에 따라서 우도가 달라지게 되므로 우도 함수가 일종의 목적 함수가 된다. 우도를 극대화해주는 \(\boldsymbol{\beta}\)가 최대 우도 추정치, 즉 MLE(MLE, maximum likelihood estimator) \(\hat{\boldsymbol\beta}\) 이다. 즉,
\[ \hat {\boldsymbol \beta} = \text{arg max }{L({\boldsymbol \beta}|y, {\boldsymbol X})} \]
간혹 목적 함수, 즉 우도 함수가 비선형이라서 목적 함수의 최대화를 달성하는 해 \(\hat{\boldsymbol\beta}\)를 축약형(reduced form)으로 구하기 힘들다는 내용을 접하곤 한다. 이는 반쪽만 맞다. 반례로 선형 회귀 모형에서 에러 항이 정규 분포를 따른다고 가정하면 최대 우도 추정을 적용할 수 있다. 정규 분포의 우도 역시 비선형이지만, 축약형 해를 쉽게 구할 수 있다. 이때 MLE \(\hat{\boldsymbol\beta}\)은 통상적인 방법으로 구한 OLS 추정량와 동일하다. 본문에서 말했듯이, 이는 수치적인 방법이 아니라 분석적인 방법을 통해 축약형으로 도출 가능하다. 여기를 참고하라. 왜 로짓 회귀에서는 축약형 해를 구할 수 없을까? 우도 추정에서 우리가 관심이 있는 것은 목적함수를 극대화하는 \(\hat{\boldsymbol\beta}\) 값이지 우도 자체가 아니다. 따라서 원래의 우도를 적절한 형태로 변형해도 변형된 목적함수를 극대화해주는 \(\hat{\boldsymbol\beta}\)가 바뀌지 않는다면 목적 함수를 변형해도 괜찮다. 때로는 변형이 계산을 쉽게 바꿔준다. 정규분포는 오일러 수(\(e\))의 지수 위에 최적화에 필요한 파라미터가 모두 포함되어 있다. 따라서 원래 목적함수에 \(\ln(\log_e)\)를 취하면 곱셈이 덧셈으로 변하고 \(e\) 위에 지수로 올라가 있단 파라미터들이 앞으로 내려온다. 하지만 아래 식에서 보듯이 로짓 함수는 그렇지 않다.
\[ p(\boldsymbol{x_i}) = \dfrac{1}{e^{-\boldsymbol{\boldsymbol{x_i}}\boldsymbol{\beta}} + 1} \]
이 함수에 \(\ln\)을 취한다고 해서 식이 단순해지지 않는다. 로짓 함수의 경우 우도 극대화에서 축약형을 해를 구할 수 있는 변형이 없기 때문에 해당 우도를 극대화하는 파라미터를 찾기 위해서는 수치 최적화(numerical optimization)를 활용한다. 수치 최적화의 자세한 내용과 사례는 이 글을 참고하라.
계수의 의미는?
보통 기계 학습의 맥락에서 로짓 회귀는 가장 원시적인 분류기(classifier)로 소개된다. 즉 \(y_i\)의 속성을 예측하는 분류 장치이기 때문에 \(\hat{\boldsymbol\beta}\)에 특별한 의미를 부여하지 않는다. 하지만 회귀 분석을 인과관계의 추론의 활용해 온 여타 분야에서는 \(\hat{\boldsymbol\beta}\)를 어떻게 해석할 것인지는 중요한 질문이다.
먼저 OLS의 경우 변수를 어떻게 변형했는지에 따라서 다르지만, 대체적으로 \(\beta_i\)는 해당 독립 변수 \(x_i\)의 한계 효과(marginal effect)로 해석할 수 있다. 즉, \(x_i\)가 한 단위 변할 때 이에 따른 \(y_i\)의 변화량을 의미한다. 그런데, 로짓 회귀에서는 이렇게 해석할 수 없다. 앞서 보았듯이, 로짓 회귀의 추정식은 다음과 같다.
\[ \ln \dfrac{p(\boldsymbol{x_i})}{1-p(\boldsymbol{x_i})} = \underset{1 \times k}{\phantom{\boldsymbol{\beta}}\boldsymbol{\boldsymbol{x_i}}\phantom{\boldsymbol{\beta}}}\underset{k \times 1}{\boldsymbol{\beta}}, ~k = 1, 2, \dotsc, n \]
흔히 좌변의 \(\dfrac{p(\boldsymbol{x_i})}{1-p(\boldsymbol{x_i})}\)를 오즈(odds) 혹은 승산(勝計)이라고 부른다. 이때 \(\boldsymbol{\beta} = [\beta_1, \dotsc, \beta_j, \dotsc, \beta_k]\)에서 \(\beta_j\)는 독립 변수의 벡터 \(\boldsymbol{x_i}\)에 속한 \(x_j\) 한 단위가 변할 때 오즈에 미치는 영향을 뜻한다.
간혹 \(\beta_i\)를 좌변의 상태를 변화시킬 확률의 변화로 해석하는 경우가 있는데 그렇게 하면 안된다. \(x_i\)의 변화가 상태를 0에서 1로 바꾸는 데 미치는 확률에 관심이 있다면, 아래의 두 가지에 유의하자.
- OLS의 경우 회귀식 자체가 선형이기 때문에 \(\beta_i\)에 관한 해석이 쉽고 단순하다. 그냥 직선의 기울기다. 그런데 로짓 회귀에서는 그렇게 분명하지 않다. 추정하려는 식 자체가 비선형이므로 한계 효과를 구하기 위한 기울기를 ‘어디서’ 구할지가 문제가 된다. 측정 위치에 따라서 기울기가 달라지기 때문이다.
- 도출하는 방법이 크게 어렵지는 않다. 측정에는 대체로 두 가지 방식이 많이 활용된다. 독립 변수 \(x_i\) 관찰값 별로 확률값의 변화를 추정한 뒤 이를 평균하는 방식이다. 반대로 독립 변수 값의 평균에서 한번만 \(p_i\)에 미치는 영향을 추정하는 방법이다. 통계 패키지가 대체로 두 방법을 모두 지원하니 필요할 경우 찾아서 값을 구하면 되겠다. 해석과 보고 시에는 역시 주의해야 한다. 만일 첫번째 방법으로 수행했다면, \(x_i\)의 1단위 변화가 평균적으로 확률에 미치는 영향으로 표현하는 게 비교적 오해를 덜 살 것이다.
계수의 수학적인 이해
이 부분이 부담스럽다면 넘어가도 좋다. 앞서 말한 한계 효과는 \(\frac{\partial p}{\partial x_j}\)이다. 즉, 독립 변수 벡터의 한 변수\(x_j\) 가 한 단위 변할 때 확률 변화를 측정한다. 즉,
\[ p(\boldsymbol{x_i}) = \dfrac{1}{e^{-\boldsymbol{x_i}\boldsymbol{\beta}} + 1} \]
이 녀석을 그대로 미분해보자. 먼저 아래와 같이 \(p(\cdot)\)을 변형하자.
\[ \begin{aligned} p(\boldsymbol{x_i}) & = \dfrac{1}{e^{-\boldsymbol{x_i}\boldsymbol{\beta}} + 1} \\ & = \dfrac{e^{\boldsymbol{x_i}\boldsymbol{\beta}}}{1 + e^{\boldsymbol{x_i}\boldsymbol{\beta}}} \end{aligned} \]
\(\boldsymbol x_i = [x^1, \dotsc, x^k]\)이고, \(x^j\)에 대해서 미분하면 아래와 같다.
\[ \dfrac{\partial p(\boldsymbol{x_i})}{\partial x^j} = \dfrac{\beta_j e^{\boldsymbol{x_i}\boldsymbol{\beta}}}{(e^{\boldsymbol{x_i}\boldsymbol{\beta}} + 1)^2} \]
이처럼 한계 효과는 미분을 통해 간단히 도출할 수 있다. 앞서 말했던 두 가지 측정을 어떻게 구별할 수 있을지 다시 살펴보자.
\(\boldsymbol{\beta}\)의 추정치로 MLE를 통해 구한 \(\hat{\boldsymbol\beta}\)를 활용한다고 해도, 어떤 \(\boldsymbol{x_i}\)에서 측정하는지에 따라서 값이 달라진다. 평균(marginal effect at mean)에서 한 번만 측정할 것인지 아니면 \(n\)개의 모든 데이터 포인트에 대해서 계산한 뒤 이를 평균(average marginal effect)할 것인지 등의 선택이 필요하다. 보통 후자를 많이 활용하는데, 통계 패키지마다 둘 모두를 구할 수 있는 옵션을 제공한다.