Perron-Frobenius Theorem, part 1
TL; DR
- 정칙 행렬(regular matrix)의 경우 페론-프로베니우스의 정리는 아이겐밸류와 아이겐벡터에 관해서 강력한 조건을 걸어준다.
- 정칙 행렬의 경우 가장 큰 양의 유일한 실수 아이겐밸류가 존재하며, 이 값에 상응하는 아이겐벡터는 양이다.
- 이 정리를 쓸모 있게 활용할 수 있는 사례는 마르코프 체인의 극한 분포다. 이때 가장 큰 아이겐밸류는 1이 되며, 좌 아이겐벡터와 우 아이겐벡터를 활용해 마르코프 과정의 극한 분포를 아이겐벡터로 손쉽게 구할 수 있다.
Definitions
positive, nonnegative
- 양(positive): 행렬의 모든 원소가 양의 값을 지닐 때
- 비음(nonnegative): 행렬의 모든 원소가 비음일 때, 가 원래 정의다. 하지만 여기서는 “non-negative and non-zero”의 의미로 사용한다. 즉, 모든 원소가 비음이면서 행렬 혹은 벡터는 \(\mathbf 0\)이 아니다. 즉, \(z \geq 0\) with \(z \neq 0\).
벡터 \(x\), \(y\)가 있을 때 \(x > y\)는 \((x-y)\)가 양이라는 뜻이다. 앞으로 벡터와 행렬에 대해서 \(>\) 그리고 \(\geq\)는 모두 원소-단위(element-wise)를 뜻한다.
Basic facts
For \(z \geq 0\),
- If \(A \geq 0\) then \(A z \geq 0\).
- If \(A>0\) then \(A z > 0\).
- 역도 성립한다. 즉, if \(Az >(\geq)\;0\), then \(A >(\geq)\;0\)
- If \(x \geq 0\) and \(x \neq 0\), \(\pi = (\frac{1}{\boldsymbol{1}^T x}) x\)와 같은 표준화된 형태를 확률 분포로 활용할 수 있다.
- \(\pi\) 벡터에 속하는 원소 \(i\)는 \(\pi_i = \dfrac{x_i}{\sum_j x_j}\).
Regular nonnegative matrices
\(A \in \mathbb{R}^{n \times n}\) 그리고 \(A \geq 0\)를 가정하자. \(A\)는 다음의 조건을 만족할 때 정칙 행렬(regular matrix)이라고 한다; 1보다 큰 정수 \(k\)에 대해서 \(A^k > 0\)를 만족한다.
A matrix for a graph
노드들 간의 그래프 관계를 가장 쉽게 나타낼 수 있는 것이 행렬이다. 즉, \(i, j \in \{ 1, 2, \dotsc, n \}\) 일 때, \(A_{ij}>0\)이면 \(i \to j\)의 엣지를 그릴 수 있음을 나타낸다. 이때 \((A^k)_{ij} > 0\)와 동치는 \(i\) 노드와 \(j\) 노드를 연결하는 길이 \(k\)의 경로가 존재함을 의미한다. 이때 \(A\)가 정칙 행렬이라는 가정의 의미는 무엇일까? 이는 모든 노드에서 다른 어떤 노드로 이동하는 임의의 \(k\) 길이의 경로가 항상 존재한다는 뜻이다.
Examples
Not regular 비정칙
\[\begin{bmatrix} 1& 1 \\0& 1 \end{bmatrix}\]
\[\begin{bmatrix} 0& 1 \\1& 0 \end{bmatrix}\]
Regular 정칙
\[\begin{bmatrix} 1& 1& 0 \\0& 0& 1\\ 1&0&0 \end{bmatrix}\]
- 정칙 행렬이 아닌 경우에는 \(A^k(k \geq 1)\)을 하더라도 같은 자리에 0이 남게 된다.
- \(A\)가 정칙 행렬이라면 \(A \geq 0\)이더라도 \(A^k > 0\)가 된다.
Perron-Frobenius theorem
증명은 일단 생략하자. 그리 어렵지 않지만 페론-프로베니우스 정리 자체가 중요하기 때문에 이에 집중하겠다.
For regular matrices
\(A \geq 0\)이고 \(A\)가 정칙 행렬이면 아래를 모두 만족한다.
- 아이겐밸류 \(\lambda_{\rm pf}\)는 실수이며 양이다.
- 좌 아이겐벡터와 우 아이겐벡터 모두 양이다.
- 다른 모든 아이겐밸류 \(\lambda\)에 대해서, \(\lvert \lambda \rvert < \lambda_{\rm pf}\)
- 아이겐밸류 \(\lambda_{\rm pf}\)의 근은 1개다.
- \(\lambda_{\rm pf}\)의 좌 아이겐벡터, 우 아이겐벡터는 유일하다(unique).
물론 아이겐벡터는 아이겐스페이스에 속하므로 벡터 전체에 대한 스케일링이 가능하다. \(\lambda_{\rm pf}\)는 행렬 \(A\)의 페론-프로베니우스의 근(혹은 PF 아이겐밸류)라고 부른다.
For nonnegative matrices
\(A \geq 0\).
- 아이겐밸류 \(\lambda_{\rm pf}\)는 실수이며 비음이다.
- \(\lambda_{\rm pf}\)의 좌 아이겐벡터, 우 아이겐벡터 모두 비음이다.
- 다른 이외의 아이겐밸류가 존재한다면, 해당 아이겐밸류 \(\lambda\)에 대해서, \(\lvert \lambda \rvert \leq \lambda_{\rm pf}\)
- 아이겐밸류, 아이겐벡터는 유일하지 않다.
Markov chain
페론-프로베니우스 정리가 가장 아름답게 활용되는 사례는 마르코프 체인 모델이다. 확률 과정(stochastic process) \(X_0, X_1, \dotsc, X_n\)이 아래와 같은 과정을 따른다고 하자.
\[ {\rm Prob}(X_{t+1} = j \vert X_t =i) = p_{ij} \]
즉, 이는 \(i \to j\)의 확률, 즉 \(i\) 상태에서 \(j\) 상태로 옮겨갈 확률을 의미한다. 마르코프 체인의 특징은 \((t+1)\) 기의 상태를 결정하는 것은 오직 \(t\) 기의 상태다. 즉, \(t-k\) for \(k=1, \dots, t\) 는 \((t+1)\)의 상태를 결정하는 데 영향을 주지 않는다. \(P\)는 이행 행렬(transition matrix) 혹은 확률 행렬(stochastic matrix)라고 부른다.
\[ P = \begin{bmatrix} p_{11}& p_{12}& \dotsc& p_{1n} \\ p_{21}& p_{22}& \dotsc& p_{2n} \\ \vdots &\vdots&\ddots&\vdots \\ p_{n1}& p_{n2}& \dotsc& p_{nn} \end{bmatrix} \]
\(P\)의 각 행의 합은 1이 된다는 점을 새겨두자. \(t\) 기에 \(i\) 상태에 있었다면, \((t+1)\) 기에는 \(1, 2, \dotsc, n\) 중 어느 하나로는 상태를 변경해야 한다.
행 벡터 \(p_t \in \mathbb{R}^n\) 를 \(X_t\)의 분포라고 하자.
\[ {(p_t^T)}_i = {\rm Prob}(X_t = i) \]
를 의미한다. 즉, \(t\) 기에 \(i\) 상태가 실현될 혹은 존재할 확률이다. \((t+1)\) 기의 확률 분포를 벡터로 표현하면 다음과 같다. \(p_{t+1} = p_t P\).
확률 행렬를 활용해서 마르코프 체인의 문제를 어떻게 풀까? 일단 적당한 형태의 확률 행렬 \(P\)가 있다고 하자. 즉 \(P\)는 비음이고 \(P^k > 0\)이 성립한다(즉, \(P\)는 정칙 행렬). \(P\)에 페론-프로베니우스의 정리를 적용할 수 있다! 즉,
- 아이겐밸류 \(\lambda_{\rm pf}\)는 실수이고 양수이며 유일하다.
- 좌 아이겐벡터, 우 아이겐벡터 모두 양수이고 유일하다(unique).
- \(\lambda_{\rm pf}\)를 제외한 다른 모든 아이겐밸류 \(\lambda\)에 대해서, \(\lambda_i < \lambda_{\rm pf}\) for \(i \neq {\rm pf}\).
\(P\)라는 확률 과정에 대해서 아래의 두 사실을 증명하도록 하자.
- 아이겐밸류 1이 존재한다.
- 1이 가장 큰 유일한 아이겐밸류, 즉 \(\lambda_{\rm pf} = 1\).
이것이 증명되면 마르코프 체인의 극한 분포를 찾는데, 페론-프로베니우스의 정리를 활용할 수 있다.
Eigenvalue 1 exists!
1의 아이겐밸류가 존재한다. 어떻게 알 수 있을까?
\[ P {\boldsymbol 1}_n = (1){\boldsymbol 1}_n \]
확률 행렬 \(P\)에 대해서 모든 원소가 1인 \(n\) 차원의 열 벡터 \({\boldsymbol 1}_n\)에 관해서 위의 식이 당연히 성립한다. 즉, 확률 행렬 \(P\)의 우 아이겐벡터는 \({\boldsymbol 1}_n\)이고 그때의 아이겐밸류는 \(1\)이다. 그러면 아이겐밸류 1에 해당하는 좌 아이겐벡터 \(\pi\) 가 존재한다고 하자. 이를 적으면 다음과 같다.
\[ \pi P = \pi (1) \]
만일 \(1\)이 아이겐밸류 중에서 가장 큰 값이라면, 페론-프로베니우스의 정리에 따라서 아이겐밸류 1에 해당하는 유일한 좌 아이겐벡터 \(\pi\)가 존재한다. 이 좌 아이겐벡터는 아이겐벡터의 특성을 지니고 있다. 즉, 어떤 상태 \(\pi\)에서 한번의 확률 과정을 거치더라도 여전히 그 상태에 머물러 있게 된다. \(\pi\)는 일종의 균형 상태로 해석할 수 있다.
1 is the largest eigenvalue!
페론-프로베니우스의 정리에 따라서 아이겐밸류 1이 가장 큰 아이겐밸류라면, 이에 상응하는 아이겐벡터 \(\pi\)는 양이며 유일하다. \(\pi\)는 스케일링이 가능하기 때문에 스케일링을 거치면 \(P\)에 의해 표현되는 마르코프 체인 확률 과정의 무한 반복, 즉 \(P^\infty\)가 수렴하는 유일한 분포가 된다. 어떻게 증명할까? 생각보다 쉽다.
Proof
만일 1 이외의 아이겐밸류 \(\hat \lambda > 1\)가 존재한다고 하자. 이제 어떤 열 벡터 \(x\)에 속하는 최대값을 \(x_{\max}\)라고 하자. 이때 \(P x\)의 결과 생산되는 열 벡터의 각 원소는 \(x_i\) for \(i = 1, 2, \dotsc, n\)의 컨벡스 결합이다. 따라서 \(Px = x^c\)에 속한 어떤 원소 \(x_i^c\)도 \(x_{\max}\) 보다 클 수 없다. 즉,
\[ x^c_i \leq x_{\max} \]
\(p_{i1} x^c_1 + p_{i2} x^c_2 + \dotsb + p_{in} x^c_n\) with \(p_{i1} + p_{i2} + \dotsc + p_{in} =1\) for \(i = 1, 2, \dotsc, n\)
그런데 \(P x = \hat \lambda x\)가 성립하고 \(\hat \lambda >1\)이기 때문에, \(x_{\max} \hat \lambda > x_{\max}\)가 성립해야 한다. 즉 모순이다. 귀류법에 따라서 \(\lambda \leq 1\)이고, 이때 아이겐밸류의 최대값은 1이다. 즉, 페론-프로베니우스의 근 \(\lambda_{\rm pf} = 1\)이다.
확률 행렬 \(P\), 아이겐밸류 1에 상응하는 좌 아이겐벡터 \(\pi^*\)라고 하자. 페론-프로베니우스의 정리 활용하면 아래와 같다.
- 좌 아이겐벡터 \(\pi^*\)는 유일하고, 모든 원소는 실수이며 양이다.
- 이를 적절하게 스케일링하면 분포가 된다.
- 마르코프 체인의 초기 상태와 무관하게 확률 과정을 반복할수록 이 분포에 수렴한다.
보통 마르코프 체인을 설명할 때 좌 아이겐밸류와 우 아이겐밸류를 구별하지 않는 경우가 있다. 이는 여러모로 손해다. 위에서 보듯이, 수렴 분포를 증명하는 과정에서 유용하게 활용된다.
행의 합을 1로 할지, 열의 합을 1로 할지는 이행 확률을 어떻게 정의할지 나름이다. \(P\)의 정의를 확인하고, 위와 같이 정의한 경우라면 1에 대응하는 좌 아이겐벡터가 극한 수렴 분포가 된다. 반대로, 확률 행렬을 \(P^T\)로 정의했다면 우 아이겐벡터가 극한 분포이다.
Definition of limiting distribution
확률 분포 \(\pi = [\pi_0, \pi_1, \pi_2, \dotsc, \pi_k]\)는 아래 조건을 만족할 때 마르코프 체인 \(P_n\)의 극한 분포라고 부른다. 만일
\[ \pi_j = \lim_{n \to \infty} P(X_n = j | X_0 = i) ,~\forall i, j \in S \]
이고
\[ \sum_{j \in S} \pi_j = 1. \]
몇 가지 점만 확인해보자.
- 극한 분포는 초기 상태에 의존하지 않는다.
- 만일 극한 분포가 존재한다면, 아래 같은 식이 성립한다.
\[ \lim_{n \to \infty} P^n = \begin{bmatrix} \pi \\ \vdots \\ \pi \end{bmatrix} \]
Limiting Behavior of Markov Chain
마르코프 체인은 어떻게 \(\pi^*\)로 수렴하게 될까? 확률 행렬 \(P\)의 아이겐밸류 \(1 = \lambda_1 > \lambda_2 \geq \dotsc \geq \lambda_n > 0\), 각각에 대응하는 아이겐벡터를 \(v_1, v_2, \dotsc, v_n\)이라고 하자. 아이겐벡터가 각각 선형독립이라고 가정하자. 이때 아이겐벡터로 구성된 \(Q\)는 가역(invertible) 행렬이다.
\(\pi^T_t = Q y_t\) 로 나타낼 수 있다. 즉 \(Q\)의 선형결합을 통해 \(n\) 차원의 임의의 벡터를 표현할 수 있다. \(\pi\)가 열 벡터이기 때문에 이를 행 벡터로 바꿨다는 점에 유의하자. 한편,
사실 기존의 \(\pi\)가 좌 아이겐벡터였다면 여기서는 이를 우 아이겐벡터로 바꾼 것이다. 물론, 확률 행렬 역시 \(P^T\)가 되어야 한다.
\[ \begin{aligned} \pi_{t+1}^T & = P^T \pi_t^T \\ Q y_{t+1} & = P^T Q_{t} y_t \\ Q^{-1} Q y_{t+1} & = Q^{-1}P^T Q_{t} y_t \\ y_{t+1} & = D y_t \end{aligned} \]
두 가지를 상기하자.
- 행렬 \(A\)와 전치 행렬 \(A^T\)는 동일한 아이겐밸류를 지니게 된다.
- D는 아이겐밸류로 구성된 대각행렬이다. 편의상 크기 순서대로 나열되어 있다고 하자.
\(\det(A^T−\lambda I) = \det((A−\lambda I)^T)=\det(A−\lambda I)\)
앞서 본 바에 따라서 \(\lambda_1 =1\)이다.
\[ y_t = \begin{bmatrix} \lambda_1& \dotsc& 0 \\ \vdots& \ddots& \vdots \\ 0& \dotsc& \lambda_n \end{bmatrix} y_{t-1}. \]
이 차분방정식의 해는 아래와 같다.
\[ y_t = \begin{bmatrix} \lambda_1& \dotsc& 0 \\ \vdots& \ddots&\vdots \\ 0& \dotsc& \lambda_n \end{bmatrix}^t y_{0} = \begin{bmatrix} \lambda_1^t& \dotsc& 0 \\ \vdots& \ddots& \vdots \\ 0& \dotsc& \lambda_n^t \end{bmatrix} y_0 \]
\(y_0 = [c_1, \dotsc, c_n]^T\)라고 두면, \(y_t = [c_1 \lambda_1^t, \dotsc, c_1 \lambda_n^t]^T\)가 된다. \(Q = [v_1, \dotsc, v_n]\)가 아이겐벡터 \(v_i\)로 구성된 매트릭스라고 할 때, \[ \pi_t^T \equiv Q y_t = c_1 \lambda_1^t v_1 + \dotsb + c_1 \lambda_n^t v_n. \]
이제 \(t \to \infty\)를 적용해보자. \(\lambda_i < \lambda_1 = 1\) for \(i = 2, 3, \dotsc, n\)이므로, \(\pi_{\infty}^T = c_1 v_1\)가 된다. \(v_1\)이 표준화된 확률 분포 벡터이므로 \(c_1 =1\)이어야 한다.
Appendix: Irreducibility and Aperiodicity
마르코프 체인이 수렴하는 분포를 갖게 될 조건으로 보통 두 가지 조건, 기약성(irreducibility) 그리고 비주기성(aperiodicity)이 제시된다. 먼저 간단히 둘의 내용을 살펴보자.
Irreducible matrix
기약성의 정의는 아래와 같다.
\(P\)가 확률 행렬이라고 할 때, 상태 \(x\), \(y\)에 대해서 양의 실수 \(j\), \(k\)가 존재하면, 두 상태는 서로 교류할 수 있다고 칭한다.
\[ P^j (x, y) > 0~~\text{and}~~P^k(y,x) > 0 \]
이 정의의 의미는 무엇일까? 일정한 상태를 거치면 \(x \to y\) 그리고 \(y \to x\)로 옮기는 것이 확률적으로 가능하다는 뜻이다. 기약성이란 모든 상태가 교류할 수 있는 상태를 뜻한다. 다시 말하면 어떤 상태에 들어가서 여기서 빠져나올 수 없는 경우가 발생한 가능성이 없을 때 기약성이 성립한다.
Irreducible
\[\begin{bmatrix} 0.9& 0.1& 0.0 \\0.4& 0.4& 0.2\\ 0.1& 0.1& 0.8 \end{bmatrix}\]
Reducible
\[\begin{bmatrix} 1.0& 0.0& 0.0 \\0.1& 0.8& 0.1\\ 0.0& 0.2& 0.8 \end{bmatrix}\]
Aperiodic matrix
대충 말하면 마르코프 체인 위의 이동이 예측 가능한 형태로 이루어질 수 있으면 안된다. 먼저 예를 보도록 하자.
\[\begin{bmatrix} 0& 1& 0 \\0& 0& 1\\ 1& 0& 0 \end{bmatrix}\]
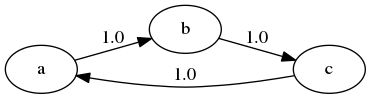
각 상태가 일정한 간격으로 존재하게 된다. 즉,
- 1번, 2번, 3번 상태는 \(\{ k, k+3, k+6, \dotsc \}\) 번째에 존재하게 된다.
주기성(periodicity)의 수학적인 정의는 다음과 같다.
\[ k = {\rm gcd} \{ n > 0~|~{\rm Pr}(X_n = i | X_0 = i) > 0 \} \]
gcd란 greatest common divisor, 즉 최대공약수를 의미한다. 만일 해당 상태로 \(\{ 6, 8, 12, \dotsc \}\) 번에 돌아갈 확률이 양이라면, gcd는 2가 된다.
확률 행렬의 원소가 0, 1로만 되어 있지 않아도 주기 행렬이 될 수 있다는 사실에 유의하자.
이때 \(k > 1\)이면 주기 행렬이고 \(k=1\)이면 비주기 행렬이다. \(k=1\)의 의미는 무엇일까? \(t\) 기에 상태 \(s\)에 있을 때, \(t+1\) 기에 역시 \(s\)에 있을 확률이 양이라는 뜻이다. 그리고 확률 행렬을 구성하는 모든 상태에 주기성이 없을 때, 이러한 확률 행렬을 비주기 행렬이라고 한다.
Regular matrix vs irreducible and aperiodic matrix
페론-프로베니우스 정리에 따르면 정칙 행렬일 때 극한 분포가 존재하게 된다. 정칙 행렬과 기약 행렬, 비주기 행렬 사이의 수학적 관계는 어떨까? 결론부터 말하면, 둘은 동치다. 증명은 간단하다.
- A: 정칙 행렬
- B: 기약 행렬이면서 비주기 행렬
A → B
Irreducible
정칙 행렬이면 \(P^k > 0\)이다. \(P^{k+1}\)의 \(i\) 행 \(j\) 열의 원소는 다음과 같다.
\[ p_{ij}^{k+1} = \sum_{t=1}^{n} p_{it} p_{tj}^k > 0 \]
위의 식이 성립하는 이유는 정칙 행렬의 경우 적어도 하나의 \(t\)에 관해서 \(p_{it} > 0\)이 성립해야 한다. 만일 이것이 성립하지 않으면 정칙 행렬이 될 수 없다. 즉, \(P^{k+1} >0\)이고, \(P^{k+2}, P^{k+3}, \dotsc\)모두 양이다.
Aperiodic
\(\{k ,k+1, k+2, \dotsc\}\)의 gcd는 1이다.
A ← B
기약 행렬이면 언제나 정칙 행렬이다.
Comments
Irreducible and aperiodic
만일 확률 행렬이 기약이면 이때 비주기성 여부를 어떻게 확인할까? 행렬이 기약 행렬이라면, 해당 행렬을 구성하는 하나의 상태만 비주기성을 지니면 전체 행렬이 비주기성을 지닌다. 증명은 조금만 생각해보시라.
Why Aperiodicity?
극한 분포 존재에 비주기성은 왜 필요할까? 만일 이 조건이 성립하지 않으면 극한 분포로 계산된 것이 사실은 극한 분포라고 할 수 없게 된다. 즉,
\[ \lim_{n \to \infty} P^n \neq \begin{bmatrix} \pi \\ \vdots \\ \pi \end{bmatrix}. \]
예를 들어보자. 상태 2개이고 확률 행렬이 아래와 같다고 하자.
\[ P = \begin{bmatrix} 0 &1 \\ 1 & 0 \end{bmatrix} \] 극한 분포를 계산하면 \([\dfrac{1}{2}, \dfrac{1}{2}]\)이 나온다. 상태 1에서 출발했다면, 상태 1이 \(\{2, 4, 6\}\) 번에 나타나게 되고, 이때 gcd는 2가 된다. 이때 확률 행렬의 곱을 살펴보면 아래와 같다. \(k = 1, 2,\cdots\)에 대해서
\[ \begin{aligned} P^n & = \begin{bmatrix} 0 & 1 \\ 1 & 0 \end{bmatrix},~\text{for}~n = 2k-1 \\ P^n & = \begin{bmatrix} 1 & 0 \\ 0 & 1 \end{bmatrix},~\text{for}~n = 2k \end{aligned} \]
따라서 \(\lim_{n \to \infty} P^n\)은 수렴하지 않는다. 앞서 계산한 극한 분포는 두 극단의 평균일 뿐이다. 이때 극한 분포 역시 존재하지 않는다.